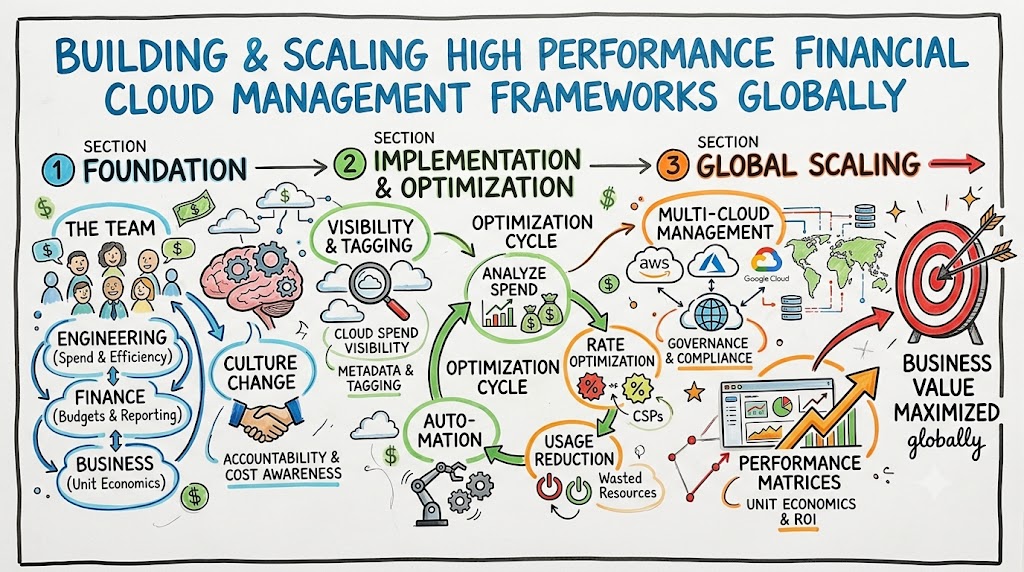
Imagine your cloud infrastructure billing platform spiking by four hundred percent in a single weekend due to an unoptimized data queries cluster. This massive financial leak goes unnoticed until the end of the monthly billing cycle, causing immediate panic across leadership teams. Traditional operations teams sit completely isolated from the finance division, which creates a massive disconnect between engineering velocity and corporate budget boundaries.
Organizations require a unified strategy to bridge these operational silos as infrastructure scales dynamically across multi-cloud environments. This comprehensive operational blueprint bridges that gap by establishing financial accountability directly within the cloud engineering lifecycle. This detailed guide unpacks the foundational steps required to assemble, scale, and nurture an elite engineering unit focused on maximizing cloud business value.
Understanding Cloud Financial Operations
Cloud Financial Operations represents an evolving management discipline that combines people, processes, and technology to optimize cloud spend. This cross-functional methodology brings accountability to cloud consumption, enabling distributed engineering teams to balance speed, cost, and quality effectively.
+---------------------------------------------------------+
| FinOps Framework Flow |
+---------------------------------------------------------+
| |
| +------------------+ Shared +-------------+ |
| | Engineering Team | <------------> | Finance/Ops | |
| +------------------+ Visibility +-------------+ |
| | | |
| v v |
| +-------------------------------------------------+ |
| | Continuous Cloud Cost Optimization | |
| +-------------------------------------------------+ |
| |
+---------------------------------------------------------+
Organizations that adopt this culture gain deep visibility into historical spending patterns while predicting future infrastructure requirements with incredible precision. Specialists who want to master these cross-functional practices can discover comprehensive learning opportunities at Finopsschool, which provides deep hands-on expertise for modern corporate scaling.
The Origin of Systems Infrastructure
The Early Industrial Bottlenecks
Traditional enterprise corporate structures relied heavily on static, on-premises data center resources to host core application infrastructure. Procurement teams purchased hardware assets upfront through heavy capital expenditure models, which resulted in massive resource over-provisioning.
Engineers worked completely separate from financial planners, creating intense friction whenever application demands required sudden server expansion. This isolated environment slowed software deployment cycles down to months, as provisioning requests spent weeks waiting inside corporate approval queues.
Moving Toward Unified Workflow Automation
The sudden arrival of public cloud environments shifted computing costs from capital investments to variable operational expenditures. This massive technological shift gave software developers the immediate power to provision infrastructure with a single click.
However, teams quickly realized that unmonitored infrastructure access led to massive, unexpected cloud bills at the end of every month. Organizations quickly adapted by implementing unified workflow automation strategies to track dynamic resources in real time.
+---------------------------------------------------------+
| On-Premises vs. Cloud Era |
+---------------------------------------------------------+
| |
| On-Premises Era: |
| [Procurement] -> [Weeks of Approvals] -> [Fixed HW] |
| |
| Cloud Era: |
| [Developer] -> [Instant Provisioning] -> [Variable $] |
| |
+---------------------------------------------------------+
Global Expansion Across Commercial Ecosystems
Modern enterprise organizations operate thousands of microservices simultaneously across multiple continents, generating highly complex billing records daily. These complex digital networks require a structured operational framework to prevent systemic financial waste across departmental lines.
Corporate leaders now deploy dedicated financial management systems globally to maintain strong profitability margins amid fluctuating market conditions. This operational philosophy ensures that every single cloud resource directly supports a core business objective.
Defining Strategic Operations Management
The Core Operational Structure
Strategic operations management unifies disparate technical metrics with corporate financial bookkeeping records across the entire organizational chart. The core framework relies heavily on continuous data ingestion pipelines that gather utilization data from cloud provider APIs.
This structured information flows into real-time dashboards, allowing team leads to allocate spending data precisely to individual product teams. The entire cycle operates on a loop of continuous monitoring, thorough analysis, and automated infrastructure optimization.
Daily Tasks of Systems Coordinators
Systems coordinators execute complex operational tasks daily to maintain an optimal balance between application performance and infrastructure costs. These cloud specialists spend considerable time tag-auditing cloud assets to ensure precise metadata tracking across all environments.
They also analyze historical resource utilization patterns to identify underused computing clusters that require immediate downsizing. Additionally, these coordinators collaborate closely with product management teams to build accurate cloud spend forecasting models for upcoming product releases.
Localized Control vs. Broad System Architecture
Granular component tracking focuses heavily on minimizing costs for single applications or specific microservices. While this localized control reduces immediate waste, it often misses the larger architectural picture of global multi-cloud ecosystems.
Broad system architecture management looks at structural patterns across entire enterprise networks to identify massive volume discount opportunities. Balancing both approaches ensures individual engineering teams stay highly agile while corporate leaders leverage global enterprise purchasing agreements.
The Efficiency Mindset
Embracing this operational philosophy requires a significant cultural shift across every layer of the engineering organization. Developers must view cost as a first-class architectural metric alongside system latency and software security parameters.
This cultural transformation replaces reactive blame-filled meetings with proactive architectural design reviews focused on long-term systemic stability. Engineering groups ultimately build a shared ownership model where code efficiency directly correlates with fiscal responsibility.
The 7 Core Principles of FinOps
1. Embracing Risk and Managing Variability
Modern cloud infrastructure scales dynamically, making static fixed budgeting approaches completely obsolete for engineering teams. Teams must accept that cloud spend fluctuates constantly based on real-time customer usage spikes and regional traffic demands.
Instead of chasing impossible fixed-cost targets, specialists focus on managing acceptable boundaries of variable expenditure. This strategy allows organizations to absorb unexpected traffic surges safely without triggering false emergency alarms.
2. Establishing Service Level Objectives (SLOs)
Operational teams establish clear, measurable spending targets that align perfectly with user performance requirements. These financial service level objectives define clear boundaries for acceptable infrastructure costs per active application user.
By tying financial performance targets directly to system performance metrics, teams ensure cost-cutting measures never degrade end-user experiences. This objective balance guides product engineering groups during rapid feature deployment phases.
3. Eliminating Toil and Manual Processes
Manual spreadsheet tracking creates significant operational bottlenecks and introduces human errors into billing calculations. Elite teams actively look for repetitive reporting tasks and use automation software to eliminate them entirely.
Engineering away these manual data collection processes frees up valuable time for strategic architectural optimization work. System coordinators focus on high-impact architectural improvements rather than building endless manual tables.
4. Monitoring & Observability Across the Pipeline
Complete visibility across the deployment pipeline prevents hidden cost spikes from turning into major corporate financial disasters. Teams build advanced telemetry dashboards that track real-time container resource utilization across various testing environments.
This continuous data visibility allows engineering leads to catch orphaned storage volumes and memory leaks long before production deployment. Observability tools transform complex raw cloud billing files into actionable architectural insights instantly.
5. Automation Over Manual Coordination
Relying on manual human reviews to shut down idle development servers creates massive operational inefficiency. Modern infrastructure frameworks use automated policy engines to clean up unused staging environments during off-peak hours.
Smart software scripts resize database clusters automatically based on historical transaction volumes without requiring human intervention. This automated approach guarantees consistent, predictable cloud resource utilization around the clock.
6. Release Engineering and Deployment Stability
Safe and predictable application delivery strategies ensure cost optimizations do not introduce dangerous architectural instability. Teams test new cloud savings plans within isolated staging environments before applying them globally across production workloads.
Continuous integration pipelines scan infrastructure-as-code files automatically to check for compliance with corporate cost policies. This preventative measure catches expensive architectural configurations before they deploy to active live environments.
7. Simplicity in Network Architecture
Complex multi-cloud networking paths frequently introduce hidden data transfer fees that rapidly inflate operational spending. Keeping cloud architecture clean, minimal, and highly organized directly reduces these unexpected financial data transfer overhead surfaces.
Engineers prioritize direct data routing paths and regional data aggregation to minimize costly inter-region networking charges. Simplified environments are significantly easier to monitor, secure, and optimize over long operational periods.
Key Operational Concepts You Must Know
SLA vs. SLO vs. SLI — Explained Simply
Understanding the explicit differences between service commitments, targets, and actual metrics forms the bedrock of modern system management.
- Service Level Agreement (SLA): The external legal commitment made directly to clients regarding total platform uptime and availability parameters.
- Service Level Objective (SLO): The internal target performance metric that engineering teams strive to maintain to satisfy the broader client agreement.
- Service Level Indicator (SLI): The actual real-time compliance measurement calculated by monitoring tools across active systems.
Error Budgets — The Game Changer for Operational Risk
Error budgets represent the total allowable room for system failure and financial variance over a specific operational timeframe. This metric balances rapid product feature innovation with foundational infrastructure stability across engineering teams.
If a team maintains a healthy error budget, developers retain full clearance to push out new features rapidly. Conversely, exhausting this budget pauses feature releases so engineers can focus exclusively on stability and cost optimization.
Toil — The Silent Productivity Killer in Infrastructure
Toil encompasses repetitive, manual, operational tasks that lack long-term strategic value and scale linearly with system growth. Examples include manually generating monthly cloud spend reports or updating machine tags by hand across various accounts.
Teams systematically calculate time spent on these repetitive tasks and set strict limits to prevent engineer burnout. Engineering teams automate these mundane workflows to focus human capital on long-term architectural health instead.
Incident Management & Postmortems
When unexpected cloud cost anomalies occur, structured incident response frameworks ensure rapid resolution and minimal financial damage. Teams conduct blameless postmortems to investigate the systemic root causes of cost overruns without pointing fingers at developers.
This cooperative culture focuses on identifying gaps in automated alerting systems rather than punishing individual engineers. Documenting these operational lessons ensures identical architectural mistakes never happen again within the organization.
Capacity Planning
Modern capacity planning balances predictive data forecasting models with the real-time elasticity of cloud service providers. Operational specialists track seasonal user traffic trends to purchase cloud commitment discounts in advance for predictable workloads.
This proactive strategy ensures organizations secure the lowest possible pricing tiers for baseline infrastructure requirements. Teams remain highly flexible, utilizing on-demand scaling only for unpredictable operational traffic spikes.
The Four Golden Signals of Pipeline Performance
Monitoring system performance requires close observation of four foundational operational metrics that reflect core architectural health.
- Latency: The total time taken to process data requests across the deployment pipeline.
- Traffic: The overall volume of demand flowing through infrastructure nodes simultaneously.
- Errors: The total rate of requests failing across application routing paths.
- Saturation: The fraction of system resources utilized compared to maximum theoretical capacity limits.
Platform Implementation vs. Culture — What’s the Real Difference?
The Philosophy Difference
Many organizations mistakenly treat financial optimization as a software tool installation process rather than a deep cultural transformation. Implementing a cloud management platform provides raw numbers, but it cannot fix broken engineering consumption habits.
The cultural philosophy focuses heavily on shifting developer mindsets toward continuous, proactive financial accountability during the initial coding phase. True optimization occurs when engineering teams organically build efficient code from day one.
| Dimension | Cultural Framework | Technical Implementation |
| Primary Focus | Human behavior, shared ownership, accountability | Tool deployment, automation scripts, data dashboards |
| Core Goal | Foster long-term optimization mindset | Provide immediate visibility into system metrics |
Roles & Responsibilities Compared
- FinOps Practitioner: Focuses on driving organizational alignment, building forecasting models, and establishing corporate tagging standards across departments.
- Cloud Engineer: Focuses on building automated resource optimization scripts, resizing container clusters, and refactoring inefficient application code paths.
- Finance Analyst: Focuses on auditing monthly cloud billing invoices, managing enterprise amortization schedules, and validating macro-level budget allocations.
- Product Owner: Focuses on tracking unit economics per feature, managing product profit margins, and prioritizing optimization backlog tasks.
Can You Have Both Disciplines?
These two operational management methodologies coexist harmoniously within high-performing technology enterprises to drive maximum structural efficiency. Cultural frameworks guide human decision-making processes, while advanced technical platforms provide the data validation required for optimization.
+---------------------------------------------------------+
| Coexistence of Disciplines |
+---------------------------------------------------------+
| |
| +-----------------------------------------------+ |
| | CULTURAL FRAMEWORK | |
| | (Guides Behavior & Shared Ownership) | |
| +-----------------------------------------------+ |
| ^ |
| | Mutual Support |
| v |
| +-----------------------------------------------+ |
| | TECHNICAL IMPLEMENTATION | |
| | (Provides Telemetry & Automation) | |
| +-----------------------------------------------+ |
| |
+---------------------------------------------------------+
Engineering teams leverage automated tools to surface cost anomalies, then utilize cultural pathways to coordinate remediation efforts seamlessly. Integrating both strategies helps organizations avoid the common pitfalls of tool fatigue and operational friction.
Which One Should Your Team Adopt?
| Organization Status | Recommended Primary Focus | Strategic Action Plan |
| Early-stage startups with chaotic environments | Cultural Framework | Establish basic cost awareness and tagging rules early |
| Large enterprises with massive billing complexity | Technical Implementation | Deploy centralized management platforms to handle data load |
Real-World Use Cases of Modern Operations
How Tech Leaders Use Operational Metrics
Global streaming platforms track financial unit economics per streaming hour to evaluate real-time infrastructure delivery efficiency. Engineers analyze container orchestration data alongside content delivery network bills to optimize global video distribution paths.
This data-driven approach allows product managers to calculate the exact profitability margins of specific media features instantly. Consequently, leadership teams make highly informed decisions regarding future content Delivery infrastructure expansions.
Chaos Engineering Approaches to Resilient Systems
Prominent e-commerce software companies intentionally inject simulated cost anomalies and resource failures into testing clusters during off-peak hours. This practice ensures that automated system auto-scaling policies react correctly when production storage components face sudden traffic load.
Engineers uncover hidden architectural dependencies that generate unnecessary data transfer costs during system recovery phases. Simulating disruptions builds highly resilient cloud networks that handle unexpected operational spikes seamlessly.
Handling Reliability at Massive Scale
Enterprise communication platforms manage millions of concurrent user connection pools across globally distributed cloud networks daily. Operational specialists utilize dynamic resource scheduling systems to move workloads across regions based on energy costs.
This sophisticated scaling framework guarantees uninterrupted service delivery while continuously driving down computing expenses in real time. The underlying infrastructure dynamically adapts to global user traffic demands without human intervention.
High-Availability in Fintech Operations
Financial transaction networks maintain a strict zero-tolerance policy for system downtime and unexpected architectural latency overhead. Teams configure redundant, multi-region database clusters that sync data continuously while strictly monitoring cross-region transfer fees.
They use real-time operational dashboard applications to monitor performance metrics alongside financial expenditure paths simultaneously. This setup protects the system from outages while keeping cloud computing spend completely predictable.
Scaled-Down but Essential Systems for Startups
Early-stage software teams often operate with limited capital runways, making early resource optimization absolutely critical for business survival. Startups implement basic automated scheduling policies to turn off non-essential database nodes outside of working hours.
This simple proactive measure prevents early financial burn without requiring complex enterprise software suites. Building these simple habits early establishes a strong foundation for scaling up operations later.
Common Mistakes in Operations Engineering
Mistake 1 — Confusing System Management with Just Being On-Call
Many companies mistake modern financial management for basic system monitoring and reactive page-alert management duties. True efficiency requires proactive architectural design, automated infrastructure provisioning, and continuous developer feedback loops.
Forcing engineers to respond to cost alerts manually without providing optimization tools creates intense operational frustration. Teams must shift from reactive firefighting to automated architectural governance.
Mistake 2 — Setting Unrealistic SLOs
Demanding perfect, unyielding infrastructure cost targets across every environment stops product feature delivery completely. Engineering teams spend excessive time building complex, over-engineered optimization mechanisms for non-production environments.
This misallocated effort slows down product launch velocity and causes significant burnout among development teams. Leaders must establish realistic targets that match the actual business value of each workload.
Mistake 3 — Ignoring Toil Until It’s Too Late
Ignoring manual cloud ledger updates creates substantial operational debt that blocks engineering velocity over time. Teams eventually find themselves spending more time managing manual tracking spreadsheets than building product features.
This systemic accumulation of manual overhead stalls corporate innovation and degrades software deployment quality. Organizations must prioritize automation early to keep infrastructure teams agile and highly productive.
Mistake 4 — Skipping Blameless Postmortems
When severe budget overruns happen, blaming individual developers creates a toxic culture of fear across teams. Engineers begin hiding structural cloud configuration mistakes, which prevents organizations from fixing underlying systemic issues.
Skipping objective postmortem analysis ensures identical architectural failures recur across different business units. Teams must embrace open communication to identify and patch system vulnerabilities collectively.
Mistake 5 — Monitoring Without Actionable Alerts
Flooding engineering communication channels with non-critical cost notifications causes widespread alert fatigue across departments. Developers quickly build email filters to ignore these messages, leading them to miss actual cost spikes.
Every single cost notification must connect directly to a clear, actionable remediation step. Keeping alerts relevant ensures critical infrastructure issues get resolved before they hit the corporate balance sheet.
Mistake 6 — Not Involving Operational Engineers in the Design Phase
Building complex cloud applications without consulting operational specialists leads to massive structural cost overruns down the road. Developers frequently choose expensive, unoptimized storage patterns that are incredibly difficult to refactor after launch.
Bringing operational insights into initial design phases prevents expensive architectural mistakes before any code is written. This proactive collaboration guarantees long-term system sustainability and financial health.
Essential Infrastructure Tools & Technologies
Monitoring & Observability
+-------------------------------------------------------------+
| Observability Telemetry Pipeline |
+-------------------------------------------------------------+
| |
| +-------------------+ |
| | Prometheus / | --( Metrics & Time-Series Data )--> |
| | Datadog Ingestion | |
| +-------------------+ |
| v |
| +-----------------------+ |
| | Grafana Visualization | |
| +-----------------------+ |
| |
+-------------------------------------------------------------+
Prometheus gathers real-time time-series performance metrics across containerized cloud environments with high efficiency. Teams use Grafana dashboards to visualize these metrics alongside financial cost models for unified analysis.
Datadog and New Relic provide deep application performance monitoring capabilities, tracing data paths across complex microservices. These observability platforms ensure visibility into hidden infrastructure performance bottlenecks.
Incident Management
PagerDuty organizes real-time incident response workflows by routing critical alerts to on-call engineering teams immediately. This platform ensures major cloud cost anomalies receive prompt attention from designated specialists.
Teams integrate incident response systems with collaboration tools to coordinate rapid remediation sessions across departments. Streamlining communication workflows minimizes downtime and curtails financial waste during critical system outages.
CI/CD & Release Engineering
Jenkins and Argo CD power modern deployment pipelines, automating application delivery across containerized clusters safely. Spinnaker provides robust multi-cloud continuous delivery capabilities, enabling safe progressive deployment strategies.
These release automation tools run policy checks on infrastructure code before launching resources into production. Automating deployment pipelines ensures consistent environment configurations and predictable resource usage patterns.
Chaos Engineering
Chaos Monkey injects controlled infrastructure failures into production environments to test system resilience under stress. This practice uncovers hidden configuration flaws that cause expensive resource scaling loops during outages.
Engineers use controlled failure injection to validate that automated recovery scripts function correctly without human intervention. Building resilient systems prevents runaway infrastructure costs during real-world platform disruptions.
SLO Management
Nobl9 helps organizations define, track, and manage service level objectives against real-time user performance metrics. The platform converts raw telemetry data from monitoring tools into actionable error budget calculations.
This centralized visibility allows engineering teams to balance system reliability goals with rapid software feature delivery. Tracking these objectives keeps cross-functional teams aligned on organizational performance standards.
How to Become an Operations Expert — Career Roadmap
Skills Every Specialist Must Have
Aspiring specialists must build a strong foundation in Linux terminal operations, shell scripting, and systems configuration. Mastery of Python or Go allows engineers to build custom automation tools to manage cloud resources efficiently.
+---------------------------------------------------------+
| Specialist Skill Stack |
+---------------------------------------------------------+
| |
| +-------------------------------------------------+ |
| | Cloud Telemetry (Prometheus, Grafana, Nobl9) | |
| +-------------------------------------------------+ |
| | |
| +-------------------------------------------------+ |
| | Automation & Scripting (Python, Go, Bash) | |
| +-------------------------------------------------+ |
| | |
| +-------------------------------------------------+ |
| | Core Systems (Linux Terminal, Cloud Networking) | |
| +-------------------------------------------------+ |
| |
+---------------------------------------------------------+
Deep knowledge of cloud networking routing rules, IAM security policies, and container orchestration architectures is essential. Developing these technical proficiencies ensures professionals can optimize complex cloud ecosystems effectively.
The Professional Learning Path
The learning path begins with managing single application servers and learning basic infrastructure-as-code principles. Professionals progress to managing containerized microservices across dynamic multi-cloud environments.
Next, engineers integrate cloud cost visibility tools into continuous integration pipelines to automate policy enforcement. Senior architects focus on designing global, self-healing systems that optimize resource utilization automatically.
Certifications Worth Pursuing
Industry-recognized credentials validate an engineer’s ability to optimize complex cloud networks under real-world conditions. Certified FinOps Practitioner and FinOps Professional designations show deep knowledge of cloud financial management principles.
Advanced cloud architecture credentials from major cloud providers also validate an expert’s technical implementation skills. Earning these certifications enhances professional credibility and opens up leadership opportunities worldwide.
Educational Resources with Finopsschool
Professionals can accelerate their career development by exploring the structured learning programs available at Finopsschool. The educational platform offers deep architectural training courses designed by industry specialists.
Students gain hands-on experience by working through real-world cost optimization scenarios in simulated environment labs. Master these principles to lead high-performing operational teams within modern technology companies.
The Future of Systems Management
AI and Automation in System Optimization
Machine learning algorithms are redefining how modern organizations monitor and optimize cloud infrastructure. Automated anomaly detection tools identify subtle spend variations long before they break corporate budgets.
+---------------------------------------------------------+
| AI-Driven Tuning |
+---------------------------------------------------------+
| |
| [Raw Telemetry Data] -> [ML Anomaly Engine] |
| | |
| v |
| [Automated Workload Tuning] |
| |
+---------------------------------------------------------+
AI-driven optimization systems analyze utilization patterns to adjust database sizing parameters automatically in real time. This shift toward intelligent automation allows systems to maintain optimal efficiency without human intervention.
Platform Engineering — The Evolution of Infrastructure
Platform engineering teams build unified internal developer portals that abstract away complex cloud infrastructure configuration tasks. These self-service platforms embed cost compliance policies directly into pre-approved deployment templates automatically.
Developers launch application environments quickly without worrying about underlying resource optimization rules. This approach maintains high engineering velocity while ensuring consistent cost governance across the entire organization.
Management in Cloud-Native & Kubernetes Environments
Containerized microservices introduce unique scaling dynamics that make traditional cost tracking methods ineffective. Teams implement advanced open-source allocation tools to track resource costs down to individual Kubernetes namespaces.
Managing dynamic container networks requires continuous monitoring of shared cluster overhead and node auto-scaling boundaries. Mastering container metrics helps organizations eliminate waste within large, multi-tenant computing environments.
Operational Skills That Will Matter Most
The next generation of infrastructure experts must balance deep technical engineering skills with solid financial literacy. Professionals need to translate raw infrastructure metrics into business unit economics that corporate executives understand.
Expertise in building automated governance policies and data pipelines will become highly sought after across industries. Cultivating this dual-domain knowledge ensures specialists remain valuable assets as corporate cloud ecosystems evolve.
FAQ Section
- What is the standard career path for an infrastructure optimization specialist?Professionals typically start as systems engineers or cloud administrators before specializing in cloud financial management fields. Over time, they move into senior optimization roles, platform engineering leadership positions, or corporate cloud architectural management seats.
- How do organizations calculate the return on investment for dedicated optimization teams?Companies measure success by tracking reductions in monthly cloud waste alongside improvements in product delivery efficiency metrics. The financial savings achieved through automated resource sizing usually cover the team’s operational costs within months.
- What are the average salary trends for professionals in this domain?Demand for specialized infrastructure optimization skills drives premium compensation packages across global technology markets. Senior practitioners and cloud architects frequently command top-tier salaries that match elite software engineering roles.
- Which cloud billing tools should early-stage startups implement first?Startups should use native cloud cost toolsets to establish basic budget tracking and anomaly alerts early. As systems expand, teams can adopt specialized open-source tools to manage multi-tenant environments without massive software overhead.
- How does automated resource optimization affect overall software deployment velocity?Integrating automated cost governance directly into CI/CD pipelines prevents expensive deployment mistakes without slowing down development teams. Clear infrastructure templates help developers launch optimized code safely without manual review bottlenecks.
- Why is a blameless corporate culture critical for long-term operational success?A blameless culture encourages engineering teams to share cost anomalies openly instead of hiding mistakes out of fear. This transparency allows organizations to run thorough postmortems, fix systemic root causes, and build resilient infrastructure.
Final Summary
Sustaining healthy cloud infrastructure requires a balance of automated tracking tools, clear performance metrics, and a shared engineering culture. Organizations must move past reactive budgeting habits and embed financial accountability directly into the software development lifecycle. Treating cost as a primary architectural metric helps teams eliminate wasteful spend while maintaining high system reliability.
The future of infrastructure management belongs to organizations that automate governance policies and unify cross-functional workflows seamlessly. Investing in modern engineering education empowers teams to build highly scalable, cost-effective digital platforms. Start your optimization journey today by exploring the professional training programs at Finopsschool to master cloud ecosystem design.