Imagine a massive, unpredicted cloud billing surge completely freezing your software engineering deployment velocity on a Friday afternoon. This stressful scenario happens frequently when companies scale their infrastructure across multiple distinct public cloud ecosystems without unified financial oversight. Modern cloud-native engineering groups frequently face these exact operational bottlenecks due to runaway infrastructure expenses and a complete lack of daily spending visibility.
To solve this problem permanently, engineering groups implement a dedicated framework called cloud financial operations. The Role of FinOps in Multi-Cloud Cost Optimization refers to the strategic integration of financial accountability, data science, and systems engineering across diverse cloud platforms like AWS, Azure, and Google Cloud. Consequently, this operational paradigm ensures that every software engineering deployment decision balances technical performance directly with corporate financial efficiency.
This comprehensive, deep-dive guide covers everything from historical infrastructure bottlenecks to modern multi-cloud financial architectures. You will explore critical telemetry metrics, real-world deployment frameworks, and cultural methodologies required to maximize system performance while minimizing waste. By mastering these core operational strategies, your engineering team can completely transform its cloud spending patterns from an unpredictable burden into a predictable competitive advantage.
You can rapidly accelerate your organizational mastery of these complex architectural practices by checking out the specialized training curriculum at Finopsschool. Through their expert-led educational paths, software engineers and finance professionals learn to collaborate seamlessly to eliminate cloud waste. Let us dive deep into the fundamental building blocks of modern operational cost governance.
The Origin of Systems Infrastructure
The Early Industrial Bottlenecks
Traditional enterprise IT management operated within siloed data centers where hardware procurement took several months to finalize. During this era, systems administration teams worked completely isolated from corporate finance departments and application development groups. Because of this massive organizational gap, engineering teams routinely over-provisioned physical server infrastructure to handle rare peak traffic spikes.
Unfortunately, this legacy operational model created immense financial waste because expensive compute resources remained completely idle for most of the year. Finance teams lacked any granular visibility into how specific software applications consumed hardware power or storage resources. Ultimately, these structural silos slowed down software delivery cycles while driving up capital expenditures.
Moving Toward Unified Workflow Automation
The sudden emergence of public cloud platforms promised to resolve these infrastructure bottlenecks by introducing instant, on-demand resource provisioning. However, this immediate accessibility created an entirely new operational issue because software developers could spin up expensive virtual instances with a single click. Without centralized governance, corporate cloud budgets quickly spiraled out of control across decentralized teams.
To address these challenges, forward-thinking tech enterprises began breaking down traditional team boundaries to build unified workflow automation pipelines. This major transition combined infrastructure provisioning with automated policy enforcement and real-time cost tracking mechanisms. As a result, organizations successfully shifted from rigid, slow hardware cycles to highly flexible, automated cloud environments.
Global Expansion Across Commercial Ecosystems
Over time, these unified operational frameworks quickly spread from elite Silicon Valley technology firms into massive, global commercial enterprises. Organizations operating within highly regulated fields like banking, healthcare, and retail rapidly discovered that a single cloud provider rarely met all their complex operational requirements. Therefore, these global enterprises deliberately adopted multi-cloud architectures to maximize system availability and avoid vendor lock-in.
However, managing financial workflows across multiple distinct cloud providers introduced unprecedented structural complexity. Every public cloud vendor utilized completely unique billing formats, different API metric naming conventions, and vastly different pricing models. This multi-cloud expansion forced the global technology industry to establish a highly standardized, engineering-driven financial discipline.
Defining Strategic Operations Management
The Core Operational Structure
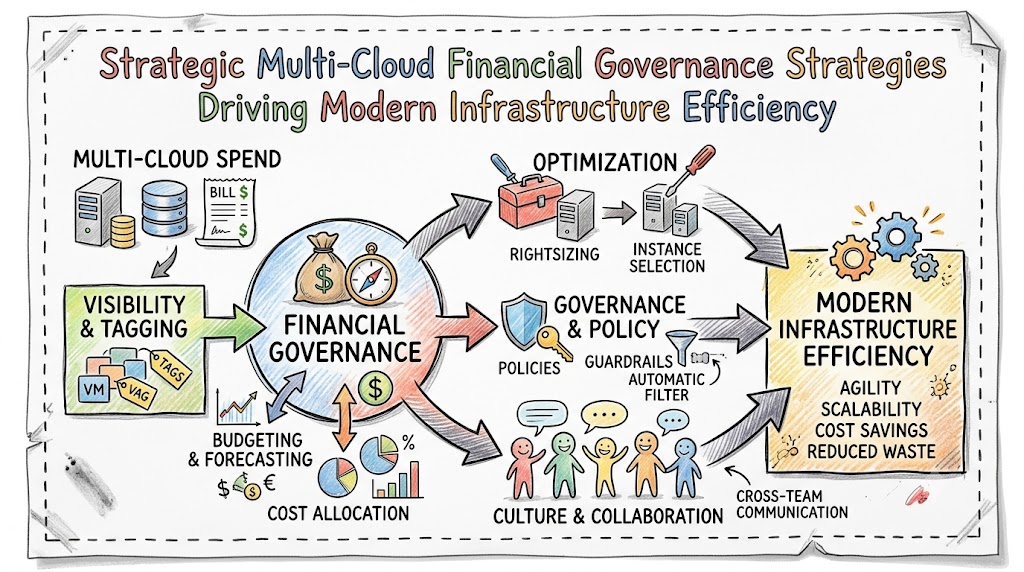
The fundamental architecture of multi-cloud cost optimization relies heavily on establishing a continuous, data-driven feedback loop across the entire enterprise. This modern operational structure integrates real-time billing APIs, centralized telemetry logging pipelines, and automated tagging validation engines. By aggregating this diverse data, the system successfully routes granular cost metrics directly to the engineering teams responsible for those specific workloads.
[Cloud Billing APIs] ---> [Centralized Telemetry Pipeline] ---> [Automated Tagging Engine]
|
v
[Engineering Teams / Cost Allocation]
Furthermore, this structural framework operates across three distinct iterative phases: Inform, Optimize, and Operate. The Inform phase provides complete visibility into multi-cloud spending, while the Optimize phase empowers teams to discover and eliminate resource waste. Finally, the Operate phase continuously evaluates everyday engineering decisions against real-time business value metrics.
Daily Tasks of Systems Coordinators
Systems financial coordinators and cloud infrastructure engineers execute a wide variety of highly specialized tasks on a daily basis to keep environments lean. They consistently audit massive multi-cloud billing files to identify immediate anomalies, untagged assets, and completely unutilized storage volumes. Additionally, these specialists regularly configure automated scheduling policies that safely shut down non-production development environments during off-peak hours.
Another critical daily responsibility involves managing and optimizing long-term commitment instruments, such as AWS Savings Plans or Azure Reserved Instances. Coordinators also collaborate directly with product delivery squads to help them architect applications with cost efficiency embedded into the initial design. Through continuous data analysis, they ensure that system performance remains exceptional without exceeding allocated budgets.
Localized Control vs. Broad System Architecture
Balancing granular, localized resource control with wide-ranging system architecture represents a major operational challenge in multi-cloud environments. Localized control focuses on optimizing individual infrastructure components, such as adjusting the memory configuration of a single microservice container. While this micro-level optimization helps, it can sometimes create unintended bottlenecks in other dependent areas of the cloud pipeline.
Conversely, broad system architecture looks at the entire multi-cloud ecosystem as a single, interconnected machine. This macroscopic viewpoint allows teams to make structural decisions, such as routing traffic dynamically to the most cost-effective cloud region based on real-time spot pricing. Successful organizations combine both approaches by using localized automation tools that operate safely within a well-designed global architectural framework.
The Efficiency Mindset
Transitioning to a highly optimized multi-cloud environment requires a profound cultural shift that prioritizes long-term systemic stability and fiscal efficiency. Engineers must view cost as a first-class architectural metric, treating an unexpected budget overrun with the same urgency as a critical software bug. This efficiency mindset encourages engineering squads to take personal ownership of their cloud consumption data.
When teams adopt this cultural philosophy, they move completely away from reactive, panic-driven cost cutting after a massive bill arrives. Instead, they proactively design highly resilient systems that scale down automatically when user demand decreases. Ultimately, this shared cultural responsibility enables enterprises to innovate rapidly while maintaining highly predictable operating margins.
The 7 Core Principles of The Role of FinOps in Multi-Cloud Cost Optimization
1. Embracing Risk and Managing Variability
Modern multi-cloud environments are inherently dynamic, meaning that striving for absolutely perfect, rigid budget forecasting is entirely counterproductive. Instead, engineering teams must comfortably embrace calculated systemic risk and learn to manage variable cloud spend effectively. By treating cloud infrastructure as a flexible, usage-based utility, organizations can scale resources instantly to capture new business opportunities.
Managing this variability requires setting up dynamic, statistical guardrails rather than static, inflexible spending limits. Teams utilize automated anomaly detection systems that flag unusual spending velocity instead of focusing purely on fixed monthly numbers. This approach allows software systems to expand dynamically when traffic surges, while ensuring that accidental resource leaks are caught within minutes.
2. Establishing Service Level Objectives (SLOs)
A highly successful cost optimization strategy must always pair financial data directly with clear, measurable systemic performance targets. Organizations establish specific Service Level Objectives (SLOs) to define the exact boundaries of acceptable user experience and system reliability. For example, a team might set an SLO dictating that a payment processing API must respond within 200 milliseconds for 99.9% of requests.
By defining these clear reliability targets, engineering groups can make highly informed trade-offs regarding cloud infrastructure expenses. If a system is consistently exceeding its performance SLOs by a massive margin, it indicates that the underlying cloud infrastructure is over-provisioned. Engineers can then safely downsize those cloud resources to save money without harming the actual user experience.
3. Eliminating Toil and Manual Processes
Manual infrastructure adjustments and repetitive administrative tasks represent a major hidden drain on engineering productivity and cloud budgets. This repetitive, non-value-adding manual work is known as toil, and it frequently leads to human error and inconsistent environments. To build a highly scalable multi-cloud ecosystem, teams must make a concerted engineering effort to automate these tasks out of existence.
Manual Audits (High Toil) ---> [Engineering Automation] ---> Policy-as-Code (Zero Toil)
Instead of assigning an engineer to manually hunt for unutilized cloud storage volumes every week, teams deploy automated cleanup scripts. These background processes automatically detect idle resources, notify the creator, and safely snapshot and delete them after a set period. Eliminating this manual toil frees up valuable engineering time to focus on complex, high-impact architectural improvements.
4. Monitoring & Observability Across the Pipeline
You cannot optimize what you do not measure, making deep visibility across the entire multi-cloud pipeline absolutely mandatory. Modern observability requires aggregating infrastructure metrics, application logs, distributed traces, and cloud billing data into a single, unified analytics platform. This deep integration allows systems engineers to see the exact financial cost of running a specific software feature or user transaction.
Cross-cloud observability removes dangerous operational blind spots where resource waste typically hides, such as forgotten database replicas or unattached public IP addresses. When a sudden cost spike occurs, unified monitoring tools allow engineers to trace the issue instantly back to a specific code deployment. This rapid feedback loop keeps teams highly accountable and ensures rapid remediation of structural issues.
5. Automation Over Manual Coordination
Relying on human communication and manual approval chains to manage multi-cloud infrastructure expenses creates massive operational delays. Instead, modern technical teams prioritize software-driven automation to enforce cost-governance policies directly within their deployment pipelines. This engineering approach utilizes policy-as-code frameworks to evaluate infrastructure designs automatically before they ever reach production.
For instance, if a developer attempts to deploy an excessively large and expensive virtual machine instance in a test environment, the automated CI/CD pipeline immediately blocks the change. The automated system flags the violation, suggests a highly optimized alternative instance size, and guides the developer toward a more cost-effective choice. This proactive automation prevents expensive mistakes completely without requiring slow, bureaucratic manual review boards.
6. Release Engineering and Deployment Stability
Safe, consistent, and highly predictable software deployment strategies are deeply tied to cloud cost optimization. When application releases are unstable or prone to frequent failures, organizations waste massive sums of money running redundant rollback infrastructure and emergency troubleshooting environments. Implementing disciplined release engineering practices ensures that code changes flow into production smoothly with minimal system disruption.
Teams utilize advanced deployment patterns, such as blue-green or canary releases, to validate the performance and cost impact of new code progressively. Automated testing suites continuously monitor system metrics during these gradual rollouts to detect any unexpected surges in CPU or memory utilization. Catching these efficiency regressions early ensures that wasteful code never scales across the entire multi-cloud production environment.
7. Simplicity in Network Architecture
Complex, convoluted multi-cloud network topologies frequently result in massive, unexpected data egress fees that catch financial teams completely off guard. Public cloud providers charge significant premiums when data moves across different regions, availability zones, or external cloud networks. Therefore, maintaining a highly simplified, clean, and minimal network architecture directly reduces your overall failure surface and operational expenses.
Engineers optimize these network pathways by utilizing private cloud endpoints and consolidating distributed microservices into centralized, well-organized container clusters. They also implement smart content delivery networks (CDNs) to cache high-volume data closer to end users, preventing repetitive data transfers across expensive cloud boundaries. Keeping network architectures clean and minimal makes cost tracking far simpler while significantly boosting overall system speed.
Key Operational Concepts You Must Know
SLA vs. SLO vs. SLI — Explained Simply
Understanding the practical differences between SLAs, SLOs, and SLIs is essential for balancing system performance with infrastructure costs.
- Service Level Indicator (SLI): This represents a specific, real-time metric that measures the current performance of a system, such as request latency or error rate.
- Service Level Objective (SLO): This is the target metric value or range defined by the team that the system must achieve to keep users satisfied.
- Service Level Agreement (SLA): This is the formal, legal contract made with external customers that defines the financial penalties the company faces if the system fails to meet the specified SLOs.
Error Budgets — The Game Changer for Operational Risk
An error budget represents the exact amount of downtime or system performance degradation that an application is allowed to experience over a specific time frame. Calculated directly from your SLOs, it acts as a dynamic regulatory mechanism that perfectly balances software innovation speed with system reliability. For example, if your application has a 99.9% uptime SLO, your allowed error budget is exactly 0.1% of total time.
Total Budget (100%) ---> [Uptime SLO: 99.9%] + [Allowed Error Budget: 0.1%]
This concept completely transforms how engineering and finance teams manage risk across multi-cloud environments. If a team has a completely full, untouched error budget, they can aggressively deploy new features and experiment with highly aggressive spot-instance cost-saving strategies. However, if the error budget is entirely exhausted due to system instability, all feature deployments are frozen, and engineering focus shifts entirely to stabilizing infrastructure.
Toil — The Silent Productivity Killer in Infrastructure
Toil refers to repetitive, manual, administrative tasks that grow linearly alongside the overall size of your multi-cloud infrastructure. Toil is completely devoid of long-term engineering value, scales poorly, and actively contributes to severe engineer burnout. Common examples include manually resetting stuck cloud connections, building custom billing spreadsheets by hand, or manually cleaning up temp files.
To systematically eliminate this productivity killer, teams must accurately calculate the time spent on manual operations every single week. If a specific team spends more than 50% of their time engaged in repetitive toil, the entire engineering workflow requires immediate restructuring. Organizations resolve this by dedicating specific engineering sprints to writing robust, self-healing automation code that resolves these recurring issues permanently.
Incident Management & Postmortems
Even the most highly optimized multi-cloud systems will eventually experience unexpected outages or sudden financial anomalies. When an incident occurs, teams require a well-coordinated, highly structured incident management process to restore normal system operations as fast as possible. Once the system is fully stabilized, the engineering team conducts a completely blameless postmortem analysis to understand the root cause.
A truly blameless culture assumes that engineers operate with good intentions and that system failures are the result of flawed processes and inadequate tooling. The postmortem document details the exact sequence of events, identifies the underlying systemic vulnerabilities, and outlines concrete preventative actions. This open, transparent process ensures that the organization learns from its operational failures rather than hiding mistakes out of fear.
Capacity Planning
Multi-cloud capacity planning involves accurately forecasting future resource requirements to ensure that infrastructure expands seamlessly ahead of major demand spikes. This practice requires analyzing historical usage trends, seasonal business patterns, and upcoming product marketing campaigns. Proper capacity planning prevents both emergency over-provisioning during traffic spikes and massive resource wastage during low-use periods.
Modern capacity planning relies heavily on automated predictive analytics rather than manual guesswork and arbitrary spreadsheets. Teams leverage cloud autoscaling groups that dynamically add or remove compute instances based on real-time traffic volume. This highly elastic approach allows organizations to maintain a lean baseline infrastructure while retaining the ability to scale up instantly when massive workloads arrive.
The Four Golden Signals of Pipeline Performance
To maintain a highly reliable and cost-effective multi-cloud pipeline, systems engineers track four critical foundational metrics closely.
- Latency: The exact time it takes for a system to process a specific request, allowing teams to spot hidden performance bottlenecks instantly.
- Traffic: A direct measure of the overall demand being placed on the system, such as total HTTP requests per second or concurrent network connections.
- Errors: The exact rate of requests that are failing, which helps engineers identify bugs or underlying infrastructure instability immediately.
- Saturation: A metric showing how close a specific resource is to its maximum capacity, such as total CPU utilization or available memory.
Platform Implementation vs. Culture — What’s the Real Difference?
The Philosophy Difference
Many organizations mistake installing a cloud cost optimization platform for actually building a sustainable cultural practice. Implementing a software tool is a purely technical exercise that involves deploying agent software and configuring API dashboards. While these tools provide excellent visibility into infrastructure spend, they cannot fix broken engineering behaviors on their own.
Building a true cost optimization culture, however, focuses entirely on changing human habits, engineering mindsets, and organizational incentives. It requires breaking down the historical walls between software developers, systems engineers, and financial analysts to establish a shared language. A tools-only approach simply highlights problems, whereas an optimization culture empowers people to actively solve them.
Roles & Responsibilities Compared
To successfully drive multi-cloud efficiency, organizations must establish clear role boundaries and explicit responsibilities across different corporate functions.
- Software Engineers: They take full ownership of their application architectures, write highly efficient code, and ensure that their services utilize appropriate cloud instance sizes.
- Cloud Infrastructure Teams: They build and maintain the global multi-cloud platform, provide automated tooling, configure baseline landing zones, and enforce policy guardrails.
- Finance and Analytics Professionals: They manage long-term cloud vendor contracts, track corporate budget allocations, analyze macro spending trends, and provide detailed financial reports.
- Product Owners: They balance the development speed of new user features against the ongoing operational cost of running those features in production.
Can You Have Both Disciplines?
Technical implementation platforms and cultural methodologies are not mutually exclusive; instead, they completely depend on each other for long-term success. A team with an incredible cost-conscious culture will eventually stall if they lack advanced automated tools to monitor complex multi-cloud data. Conversely, an organization with millions of dollars in software tools will achieve nothing if engineers completely ignore the generated alerts.
[Advanced Automation Platforms] <---> [Cost-Conscious Engineering Culture]
^
|
(Maximum Multi-Cloud Efficiency)
Modern high-performing organizations blend both disciplines seamlessly to create an automated, highly accountable multi-cloud engineering ecosystem. They use software platforms to handle the heavy lifting of data aggregation, anomaly detection, and automated policy enforcement. Concurrently, they rely on their cultural framework to guide engineering priorities and drive collaborative problem-solving.
Which One Should Your Team Adopt?
The specific balance between software tool implementation and deep cultural restructuring depends heavily on your organization’s size and technical maturity. Small, fast-moving startups should focus first on building an efficiency-first culture, using basic, native cloud tools to avoid massive software overhead. Because their teams are small, open communication and shared accountability can prevent wasteful cloud spend quite effectively.
In contrast, large enterprise organizations operating massive multi-cloud environments must implement centralized automation platforms and cultural changes simultaneously. The sheer scale and complexity of enterprise infrastructure make manual cost tracking completely impossible. Therefore, these larger teams require sophisticated software platforms to provide baseline visibility while they systematically build a modern financial engineering culture.
Real-World Use Cases of Modern Operations
How Tech Leaders Use Operational Metrics
Major global software enterprises utilize advanced telemetry tracking to tie their infrastructure expenditures directly to real-world business outcomes. Instead of simply looking at a generic monthly cloud bill, they calculate the exact infrastructure cost required to support a single active user or process a single transaction. This business-centric financial data allows executive leadership to make highly accurate pricing and product development decisions.
For example, if an enterprise discovers that running a specific feature costs more than the revenue it generates, they route engineering resources to refactor that service. They track these unit economics continuously using automated data pipelines that combine application performance metrics directly with billing logs. This high-level visibility ensures that every engineering optimization project delivers clear financial value to the bottom line.
Chaos Engineering Approaches to Resilient Systems
Modern infrastructure groups regularly practice chaos engineering, which involves intentionally injecting controlled failures into live production environments to uncover hidden architectural flaws. Teams utilize automated tools to terminate random cloud instances, induce artificial network latency, or block access to specific cloud storage regions. This proactive testing ensures that the system’s automated self-healing and failover mechanisms work perfectly under pressure.
Inject Chaos (Kill Instance) ---> [Automated Monitoring] ---> Auto-Scaling Restores System
Interestingly, this aggressive testing practice also uncovers significant opportunities for long-term cloud cost optimization. Chaos experiments frequently reveal that specific backup systems or over-provisioned standby instances are entirely unnecessary for maintaining system availability. By proving exactly how the infrastructure handles real failures, engineers can safely eliminate redundant, expensive fallback resources without risking downtime.
Handling Reliability at Massive Scale
Distributed microservices architectures handling millions of concurrent user transactions require highly dynamic cost governance frameworks. At this massive scale, static infrastructure setups fail completely, resulting in either catastrophic system outages or millions of dollars in wasted cloud spend. Large-scale tech enterprises resolve this by deploying highly advanced, automated container orchestration platforms like Kubernetes across their multi-cloud environments.
These sophisticated systems monitor real-time user demand data continuously and adjust container deployments automatically within seconds. When user traffic drops during the night, the orchestration platform automatically consolidates containers onto a minimal number of cloud instances, allowing extra hardware to shut down safely. This highly fluid operational model ensures exceptional system reliability during peak hours while driving massive infrastructure savings during low-use periods.
High-Availability in Fintech Operations
Financial technology platforms operate under incredibly strict regulatory mandates that demand zero tolerance for system downtime or data loss. To maintain this extreme level of high availability, fintech infrastructure engineers must design highly resilient, multi-region deployment architectures. However, running active server infrastructure across multiple geographic zones concurrently can quickly become financially unsustainable if unmanaged.
Fintech operations optimize these complex setups by using intelligent, data-driven traffic routing engines that dynamically balance workloads based on cost and performance. They configure their systems to utilize highly economical spot instances for non-critical background data processing tasks while reserving premium hardware exclusively for core transaction engines. This disciplined approach allows fintech platforms to meet their strict compliance targets while keeping operational expenses highly optimized.
Scaled-Down but Essential Systems for Startups
Early-stage startups must optimize their limited capital carefully, making early cloud cost governance an absolute necessity for long-term survival. While startups do not require the massive, complex automation tools utilized by global enterprises, they can still apply the core principles of cost optimization. They achieve this by utilizing fully managed, serverless computing architectures that charge strictly for the exact compute time consumed.
Startup Choice: Serverless Architecture (Pay strictly per request, zero idle cost)
By adopting serverless technologies, early-stage teams eliminate the financial burden of paying for idle, constantly running virtual servers entirely. Startups also establish basic policy guardrails early, such as automated notifications that trigger when daily cloud spending exceeds a pre-set threshold. These simple, highly effective practices allow small teams to scale their products rapidly without accumulating massive amounts of cloud financial debt.
Common Mistakes in Operations Engineering
Mistake 1 — Confusing System Management with Just Being On-Call
A very common architectural mistake is treating cloud cost optimization as a purely reactive operational task handled by an on-call engineer. When organizations adopt this flawed view, engineers spend all their time manually reacting to budget alerts after the overspending has already occurred. This reactive firefighting approach fails to address the underlying structural flaws causing the runaway cloud expenses in the first place.
True cost governance is a proactive engineering discipline that integrates financial efficiency directly into the initial software design phase. It requires building automated continuous monitoring tools, establishing clear policy guardrails, and writing self-healing infrastructure code. Shifting focus from reactive firefighting to proactive engineering ensures that wasteful infrastructure patterns are eliminated long before code ever reaches production.
Mistake 2 — Setting Unrealistic SLOs
Another frequent operational pitfall is demanding completely unrealistic system availability targets, such as a perfect 100% uptime metric. While striving for absolute perfection sounds great in theory, engineering a system to achieve zero downtime is astronomically expensive and technically impossible. Achieving each additional “nine” of reliability requires a massive exponential increase in infrastructure redundancy, backup networking, and software complexity.
Uptime Target: 99% ($) ---> 99.9% ($$) ---> 99.99% ($$$$) ---> 100% (Financially Impossible)
When management demands unrealistic SLOs, engineering teams are forced to build massive, overly complex multi-cloud architectures that drain company budgets. Furthermore, these extreme availability requirements slow software deployment speed to a crawl because teams become terrified of making changes. Organizations must set sensible, data-driven SLOs that protect user experience while keeping infrastructure expenses thoroughly optimized.
Mistake 3 — Ignoring Toil Until It’s Too Late
Many fast-growing tech companies completely ignore repetitive manual tasks, allowing their engineering teams to become slowly overwhelmed by operational toil. As multi-cloud environments expand, the time spent manually reviewing billing files and cleaning up old development instances grows exponentially. Eventually, engineers spend their entire workweek managing administrative overhead rather than writing code or improving infrastructure efficiency.
This massive accumulation of operational debt stalls software feature delivery and causes severe engineer burnout and turnover. Organizations must actively monitor their teams’ daily workloads and aggressively prioritize the automation of repetitive tasks. Investing engineering resources into building automated cost-governance tools pays massive long-term dividends by keeping teams focused on high-value optimization projects.
Mistake 4 — Skipping Blameless Postmortems
When an unexpected cloud budget overrun or infrastructure failure occurs, teams often rush to assign blame rather than fixing the system. This toxic cultural practice causes engineers to actively hide mistakes, cover up resource leaks, and resist sharing critical system visibility data. Consequently, the organization remains completely blind to systemic vulnerabilities, ensuring that the exact same costly mistakes repeat indefinitely.
Skipping deep, blameless postmortem analyses prevents teams from converting operational failures into valuable corporate learning experiences. A successful organization must embrace mistakes openly, focusing entirely on diagnosing the structural process flaws that permitted the error to happen. This transparent, blameless approach fosters a healthy culture of continuous engineering improvement and long-term multi-cloud cost stability.
Mistake 5 — Monitoring Without Actionable Alerts
Deploying comprehensive multi-cloud monitoring dashboards is completely useless if the system generates hundreds of noisy, non-actionable notifications every single day. When engineers are constantly bombarded with low-priority budget alerts that require no real action, they rapidly develop severe alert fatigue. As a direct result, they quickly learn to ignore all notifications entirely, causing them to miss critical, high-severity cost anomalies.
To prevent this dangerous operational blind spot, teams must ruthlessly audit and tune their infrastructure alerting thresholds. Every cost notification routed to an engineer’s device must be highly actionable, clearly defined, and accompanied by a specific remediation playbook. If an alert does not require immediate, concrete human intervention to save money or protect performance, it should be logged silently rather than waking up an engineer.
Mistake 6 — Not Involving Operational Engineers in the Design Phase
Excluding cloud infrastructure specialists and financial operations experts from initial software architectural discussions is a recipe for fiscal disaster. When software development teams design complex applications in complete isolation, they rarely consider long-term multi-cloud data transfer fees or resource efficiency. Consequently, they often deploy architectures that work perfectly in test environments but become financially catastrophic when scaled to millions of users.
To avoid this costly mistake, organizations must ensure that operational cost specialists have a prominent seat at the design table from day one. Involving these experts early allows teams to select the most cost-effective cloud services, design optimal data pathways, and build automation guardrails directly into the system foundation. This collaborative design approach prevents expensive architectural refactoring projects down the road, ensuring long-term profitability.
Essential Infrastructure Tools & Technologies
Monitoring & Observability
To maintain complete control over a complex multi-cloud environment, systems engineers deploy a powerful combination of monitoring and observability platforms. Open-source time-series databases like Prometheus collect granular hardware performance metrics from container clusters in real time. These metrics are then routed into advanced visualization tools like Grafana to build interactive, cross-cloud cost and performance dashboards.
For enterprise-scale environments, teams leverage comprehensive observability suites like Datadog and New Relic to trace distributed transactions across diverse cloud networks. These advanced platforms utilize artificial intelligence to correlate sudden software performance drops directly with cloud infrastructure cost changes. Having access to this unified telemetry allows engineering teams to spot inefficiencies and optimize cloud spending patterns with immense precision.
Incident Management
When critical multi-cloud outages or massive cost anomalies occur, teams rely on dedicated incident management platforms to orchestrate their response. Industry-standard tools like PagerDuty integrate directly with monitoring systems to route urgent alerts instantly to the correct on-call engineering squad. These platforms manage complex on-call schedules, automate escalation paths, and ensure that critical structural issues are addressed within minutes.
Modern incident management software also provisions secure, dedicated communication channels and diagnostic dashboards automatically as soon as an incident is triggered. This instant organization helps distributed engineering teams collaborate seamlessly under high-pressure scenarios without wasting valuable time. Resolving infrastructure failures rapidly minimizes expensive downtime and prevents unexpected cloud billing spikes from escalating out of control.
CI/CD & Release Engineering
Automating the delivery of software updates and infrastructure changes safely across multiple cloud vendors requires robust continuous integration and continuous deployment pipelines. Automated continuous integration engines like Jenkins handle the heavy lifting of compiling code, running automated tests, and scanning for security flaws. Once validated, modern continuous delivery platforms like Spinnaker and Argo CD take over to manage the rollout of infrastructure across cloud zones.
Code Commit ---> [Jenkins Test/Scan] ---> [Argo CD GitOps Deployment] ---> Multi-Cloud Realization
These GitOps-driven deployment engines monitor the live state of cloud environments continuously and compare it directly against version-controlled configuration files. If an unauthorized infrastructure change or an expensive resource leak occurs, the automation engine corrects the divergence instantly. Utilizing these disciplined release technologies ensures that multi-cloud environments remain stable, secure, and highly cost-optimized.
Chaos Engineering
Intentionally testing the resilience of multi-cloud architectures requires deploying specialized chaos engineering tools designed to inject controlled failures safely. Open-source tools like Chaos Monkey pioneered this practice by automatically terminating virtual machine instances in production environments during business hours. This continuous, aggressive testing forces engineering groups to build highly resilient, fault-tolerant software architectures that self-heal automatically.
Modern chaos platforms allow teams to simulate a wide variety of complex failure scenarios, such as blocking access to specific multi-cloud storage buckets or inducing extreme cross-region network latency. Running these controlled experiments consistently uncovers hidden configuration bugs and unneeded infrastructure redundancies before they cause catastrophic real-world outages. Ultimately, chaos engineering empowers teams to optimize their cloud configurations with absolute confidence.
SLO Management
Tracking service reliability targets accurately against real-time multi-cloud financial metrics requires utilizing dedicated Service Level Objective management platforms. Specialized tools like Nobl9 integrate directly with existing monitoring data sources to calculate error budget consumption rates continuously. These platforms provide clear, business-focused dashboards that show executive leadership exactly how software stability impacts corporate cloud expenses.
SLO management software allows engineering groups to configure automated alerts that trigger when an error budget is burning down too quickly. This early warning system enables teams to halt risky feature deployments and focus on stabilizing infrastructure long before an actual SLA violation occurs. Centralizing these metrics helps organizations strike a perfect balance between engineering innovation speed and total multi-cloud cost efficiency.
How to Become an Operations Expert — Career Roadmap
Skills Every Specialist Must Have
Breaking into the highly lucrative field of multi-cloud financial operations and systems engineering requires mastering a diverse blend of technical and financial skills. Aspiring specialists must develop a deep command of command-line interfaces, terminal operations, and advanced shell scripting languages to automate repetitive tasks. Additionally, a strong foundational understanding of networking protocols, data routing patterns, and multi-cloud security architectures is absolutely mandatory.
Candidates must also master infrastructure-as-code tools like Terraform to provision and manage complex, multi-vendor cloud environments programmatically. On the financial side, professionals need to understand basic corporate budgeting cycles, capital expenditure mechanics, and cloud unit economics concepts. Developing the unique ability to translate complex cloud architecture data into clear financial business insights makes a specialist incredibly valuable to employers.
The Professional Learning Path
The educational journey toward becoming a senior multi-cloud optimization architect begins with mastering the core fundamentals of a single public cloud platform. Start by building basic web applications, configuring virtual private networks, and setting up native billing alerts manually. Once comfortable, expand your expertise by learning containerization technologies like Docker and container orchestration platforms like Kubernetes.
Single Cloud Basics ---> Containerization (Docker/K8s) ---> Infrastructure-as-Code ---> Cross-Cloud FinOps Mastery
Next, transition into mastering multi-cloud deployments by learning how to manage infrastructure programmatically across several cloud ecosystems concurrently using automated CI/CD pipelines. Study advanced cost-governance methodologies and practice setting up deep, cross-platform telemetry monitoring dashboards. Finally, cultivate your leadership skills by learning how to drive cultural transformation, break down organizational silos, and guide cross-functional engineering teams.
Certifications Worth Pursuing
Earning industry-recognized professional certifications is an excellent way to validate your multi-cloud expertise and accelerate your career progression. Aspiring specialists should target core foundational credentials from major cloud vendors, such as the AWS Certified Solutions Architect or the Google Cloud Professional Cloud Architect. These rigorous technical certifications prove your deep understanding of designing resilient, secure, and cost-effective cloud systems.
To solidify your specialized standing within the cost governance domain, pursuing the FinOps Certified Practitioner and FinOps Certified Professional credentials is highly recommended. These specific certifications validate your mastery of the cloud financial frameworks and operational engineering practices required to manage large-scale cloud budgets. Holding a blend of technical cloud architecture and financial governance credentials makes you a highly sought-after expert in the modern tech job market.
Educational Resources with Finopsschool
When looking for structured, high-quality professional training programs, exploring the comprehensive educational resources available at Finopsschool is an exceptional choice. This specialized training organization provides an extensive selection of deep-dive courses designed specifically for software engineers, systems architects, and finance professionals. Their expert-led curriculum bridges the gap between technical cloud engineering and modern corporate financial management perfectly.
Students gain invaluable real-world experience by working through hands-on labs, analyzing complex multi-cloud billing datasets, and configuring real automation tools. Finopsschool provides interactive training paths that cater to all skill levels, from beginners discovering cloud economics to senior engineers designing enterprise cost architectures. Leveraging their specialized educational materials equips you with the practical skills required to solve real-world multi-cloud optimization challenges.
Two Comprehensive Operational Matrices
Cloud Cost Optimization Tools Analysis
The table below provides a comprehensive comparison of industry-standard tools utilized across modern multi-cloud ecosystems to track, monitor, and optimize infrastructure expenses.
| Tool Name | Core Telemetry Focus | Multi-Cloud Support | Primary Operational Benefit |
| Prometheus | Metric Collection | Universal | High-resolution time-series data gathering |
| Grafana | Data Visualization | Universal | Centralized dashboarding for heterogeneous environments |
| Datadog | Full-Stack Observability | AWS, Azure, GCP | Real-time correlation of cost spikes with code rollouts |
| New Relic | Performance Tracing | AWS, Azure, GCP | Deep diagnostic visibility across complex application pipelines |
| Nobl9 | SLO Tracking | Universal | Automated error budget calculation against spending thresholds |
Multi-Cloud Cost Drivers and Mitigation Strategies
The following table outlines the most frequent architectural sources of runaway cloud expenses and the concrete automation strategies required to resolve them.
| Cloud Resource Type | Common Waste Trigger | Cost Mitigation Strategy | Automated Remediation Action |
| Compute Instances | Over-provisioning sizing | Continuous rightsizing audits | Automated downscaling via policy-as-code |
| Block Storage | Unattached orphan volumes | Idle resource elimination | Automated snapshotting and deletion scripts |
| Network Gateways | Cross-region data transfer | Network topology cleanup | Routing local traffic through private endpoints |
| Development Sandboxes | Constant idle running | Off-peak scheduling policies | Auto-shutdown configurations during weekends |
| Container Clusters | Fixed node allocations | Dynamic cluster autoscaling | Horizontal pod autoscaling based on real-time load |
The Future of Systems Management
AI and Automation in System Optimization
The future of managing complex multi-cloud environments is becoming deeply automated, predictive, and increasingly driven by advanced machine intelligence algorithms. Legacy cost optimization practices rely heavily on engineers looking backward at historical billing data to find past mistakes. Emerging AI-driven operations systems turn this paradigm around completely by analyzing telemetry streams in real time to predict and prevent cost anomalies before they occur.
These intelligent systems analyze historical traffic patterns continuously to forecast future resource demands with incredible precision, adjusting capacity dynamically before a spike arrives. AI engines can also identify incredibly subtle software code inefficiencies that cause unnecessary CPU consumption and eliminate them automatically. Shifting from human-driven cost tracking to autonomous, AI-driven infrastructure optimization allows modern technology systems to remain perfectly lean around the clock.
Platform Engineering — The Evolution of Infrastructure
Platform engineering represents a major architectural evolution that is completely redefining how modern enterprises deliver software and manage multi-cloud infrastructure. Instead of requiring individual software developers to navigate complex cloud billing APIs and networking setups, dedicated platform teams build centralized Internal Developer Platforms (IDPs). These self-service portals encapsulate all the organization’s compliance guardrails, security standards, and cost-optimization policies directly into simple, standardized deployment templates.
Developer ---> [Internal Developer Platform (IDP)] ---> Automated Cost-Optimized Cloud Realization
When a developer requires new infrastructure resources to test a feature, they provision them instantly through the centralized IDP portal with a single command. The underlying platform handles the complex orchestration automatically, ensuring the workload runs on the most economical cloud instance size and region. This modern approach eliminates manual coordination entirely, empowering developers to ship code rapidly while ensuring perfect cost governance by default.
Management in Cloud-Native & Kubernetes Environments
As global enterprises continue to migrate their core business workloads into dynamic, containerized cloud-native ecosystems, managing orchestration environments becomes a critical priority. Kubernetes has firmly established itself as the absolute industry standard for managing containerized applications across diverse multi-cloud networks. However, the immense architectural abstraction and fluid nature of Kubernetes container clusters make traditional, server-based cost tracking methods completely obsolete.
Modern cost governance within containerized environments requires utilizing highly specialized micro-allocation tools that break down resource expenses to the individual container level. Engineers track exact CPU and memory consumption metrics continuously for every single software service, microservice namespace, and specific engineering team. Having access to this highly granular container visibility allows organizations to eliminate resource over-provisioning and maximize hardware utilization efficiency across their entire multi-cloud footprint.
Operational Skills That Will Matter Most
As the technological landscape becomes increasingly complex and data-driven, the specific professional skills required to excel as an infrastructure specialist are shifting profoundly. Relying purely on basic, manual systems administration knowledge is no longer sufficient to survive in modern enterprise environments. The most valuable technical experts of the future will be those who possess a deep mastery of advanced data analytics, statistical forecasting, and automated machine learning operations.
Professionals must cultivate a deep understanding of software engineering patterns and cloud architecture principles to design systems that are inherently cost-efficient from day one. Strong communication skills and cross-functional leadership capabilities will also become completely vital as specialists collaborate daily with corporate executive and financial teams. Developing this powerful blend of advanced data engineering expertise and financial leadership skills will define the elite multi-cloud operational masters of tomorrow.
FAQ Section
- What is the primary career path for someone entering the multi-cloud cost optimization field?Professionals typically enter this domain from foundational backgrounds in either cloud systems administration, software development, or corporate financial analytics. Aspiring specialists start by mastering a single cloud provider, then progress to learning infrastructure automation tools like Terraform and container platforms like Kubernetes. Over time, they transition into dedicated cloud financial engineering roles, ultimately advancing to senior positions like Enterprise Cloud Architect or Director of Infrastructure Optimization.
- How does this discipline differ from traditional IT infrastructure budgeting practices?Traditional IT budgeting operates on rigid, predictable annual cycles focused heavily on purchasing physical hardware assets that depreciate over time. In stark contrast, multi-cloud cost optimization manages highly dynamic, usage-based cloud expenses that fluctuate constantly based on real-time consumer demand. This modern framework shifts operational responsibility away from centralized procurement departments directly into the hands of engineering squads, utilizing continuous real-time data loops instead of static spreadsheets.
- What are the current average salary trends for certified multi-cloud financial operations experts?Due to the massive, widespread enterprise adoption of multi-vendor cloud architectures, certified cost optimization specialists command exceptionally high compensation packages in the global technology market. Junior optimization analysts and cloud infrastructure engineers typically earn highly competitive salaries, while senior architects frequently command premium enterprise compensation. Professionals who hold advanced cloud architectural certifications paired with specialized financial engineering credentials occupy a highly elite tier within the tech job sector.
- Can these infrastructure cost optimization practices be automated entirely using machine learning tools?While modern artificial intelligence and automated policy platforms handle the heavy lifting of data aggregation, anomaly detection, and basic resource rightsizing, complete automation is impossible. Complex architectural trade-offs, high-level vendor contract negotiations, and long-term strategic capacity planning require deep human business context and engineering judgment. The most effective enterprise setups combine advanced machine learning automation engines for everyday operational tasks with senior human experts guiding the global cultural framework.
- How should a global engineering team handle unexpected cross-cloud data egress fee spikes?Teams must first deploy deep, centralized telemetry monitoring tools to trace exactly which distributed microservices are transferring large data volumes across cloud boundaries. Once identified, engineers optimize these network paths by consolidating interdependent software services into the same geographic cloud region or localized container clusters. They also implement smart data compression algorithms, leverage private cloud networking endpoints, and configure content delivery networks to cache high-volume data closer to end users.
- Why are completely blameless postmortems considered so vital for long-term multi-cloud cost management?When an organization fosters a culture of blame, engineers instinctively hide mistakes, conceal expensive resource leaks, and resist sharing critical system metrics out of fear. Establishing a completely blameless postmortem culture ensures that teams analyze operational failures openly, transparently, and with a strict focus on fixing underlying process flaws. This healthy, collaborative environment allows the entire enterprise to learn from financial mistakes rapidly, build stronger automated guardrails, and prevent recurring cost anomalies permanently.
Final Summary
Maintaining exceptional performance and absolute fiscal efficiency across a massive multi-cloud infrastructure requires a profound combination of automated technology and disciplined team culture. Modern organizations must look beyond basic, reactive cost-cutting measures and instead embed automated financial accountability directly into their software deployment pipelines. By mastering the core principles of continuous observability, automated policy enforcement, and realistic objective setting, engineering teams can eliminate wasteful spending while accelerating software delivery velocity. As cloud architectures become increasingly complex, establishing a structured, data-driven financial operations framework remains the defining factor for sustainable corporate tech growth.
The future of managing cloud ecosystems belongs completely to cross-functional engineering professionals who can bridge the historical gap between technical system performance and corporate financial metrics. You can position yourself at the absolute forefront of this rapidly expanding professional field by exploring the comprehensive training programs offered by Finopsschool. Their specialized, expert-guided educational curriculum provides the exact practical skills, real-world tools, and industry credentials required to master complex multi-cloud optimization. Take the next decisive step in your professional engineering journey today by transforming how your enterprise manages its global cloud resources.