Imagine a sudden infrastructure demand spike triggering thousands of cloud containers to scale out instantly, but a misconfigured billing script fails to tear them down afterward. Consequently, your enterprise wakes up to a massive, unexpected cloud bill that completely erases the quarterly profit margin. This operational nightmare happens daily because human oversight simply cannot keep pace with dynamic cloud environments. Therefore, modern engineering teams must shift toward automated cloud financial management to maintain continuous operational equilibrium.
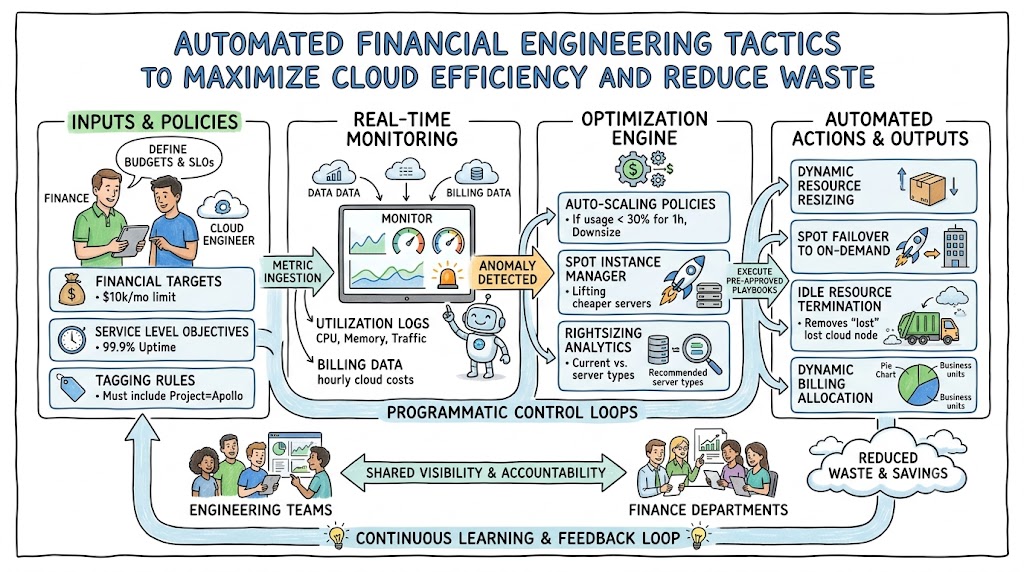
Automating financial operations means using software-driven policies, real-time metrics, and intelligent guardrails to monitor, optimize, and allocate cloud spend without human intervention. This comprehensive guide details the foundational architecture of cloud financial engineering, operational metrics, and structural deployment strategies. You will explore practical frameworks to eliminate manual waste and bridge the gap between finance and engineering teams. To master these complex strategies and elevate your organizational architecture, explore the specialized professional resources at Finopsschool to establish long-term systemic stability.
Deep Dive: Automation in FinOps for Smarter Cost Management
Automating financial operations combines data pipelines with infrastructure management tools to control expenditures systematically. Traditionally, engineering teams provisioned resources based on peak capacity estimates, which inevitably created massive, idle buffers. By embedding financial algorithms directly into continuous deployment pipelines, organizations transition from reactive accounting to real-time, proactive cloud cost optimization.
This approach works by continuously monitoring key performance signals like CPU utilization, memory allocation, and network traffic. When these metrics fall below predefined thresholds, automated orchestrators safely downsize or terminate underutilized assets. Furthermore, these systems tag resources dynamically, ensuring complete cost visibility across multi-tenant environments. The ultimate objective is to treat cloud efficiency as a primary software metric, making cost management as autonomous as automated software testing.
The Origin of Systems Infrastructure
The Early Industrial Bottlenecks
Traditional enterprise IT operations relied heavily on physical data centers and static hardware procurement pipelines. In that ecosystem, procurement teams ordered server racks months in advance based on highly speculative capacity forecasts. This siloed approach created profound friction between the engineering departments pushing for rapid feature deployment and the finance teams managing capital expenditures. Whenever hardware resources ran low, software development ground to a absolute halt while purchase approvals moved sluggishly through corporate hierarchies.
Because communication between infrastructure engineers and corporate accountants remained minimal, severe resource over-provisioning became the standard operating procedure. Teams deliberately requested twice the hardware they actually required simply to guarantee their applications would not crash during rare usage spikes. As a direct result, massive amounts of capital remained permanently locked up in idle server infrastructure that rarely ran at even twenty percent capacity. This structural inefficiency highlighted the desperate need for a more agile, data-driven approach to infrastructure management.
Moving Toward Unified Workflow Automation
The introduction of cloud computing promised to solve procurement delays by offering instant, virtualized resource provisioning. However, this shift quickly introduced a brand-new operational bottleneck: unconstrained, decentralized spending. Engineers could now spin up hundreds of virtual machines with a single API call, completely bypassing traditional financial approval workflows. Without centralized visibility, organizations rapidly accumulated vast networks of forgotten development environments and abandoned storage volumes that quietly drained corporate budgets.
To counter this chaos, pioneering tech organizations began unifying infrastructure code with real-time financial tracking mechanisms. This evolution marked the transition from static budgeting models to dynamic, software-driven workflow automation frameworks. Engineers started utilizing programmatic templates to define infrastructure, allowing financial policies to be written directly into deployment scripts. This integration ensured that every single virtual asset created automatically adhered to strict organizational spending constraints from the very moment of its creation.
[Traditional IT: Siloed, Slow Procurement]
│
▼
[Early Cloud: Uncontrolled, Manual Provisioning]
│
▼
[Modern FinOps: Unified, Automated Financial Pipelines]
Global Expansion Across Commercial Ecosystems
As cloud architecture matured into the global standard, these automated operational frameworks quickly expanded across large-scale commercial ecosystems. E-commerce platforms, global financial institutions, and SaaS enterprises realized that manual cost tracking could not scale alongside distributed microservices. Consequently, the discipline of optimizing cloud spend evolved from a niche infrastructure task into a core corporate strategy adopted worldwide.
Today, managing global infrastructure requires continuous, programmatic coordination across multiple cloud providers and geographic zones. Modern enterprises deploy intelligent systems that automatically shift workloads to cheaper regions or utilize spot markets when prices drop. This global scaling capability ensures that systems infrastructure remains highly resilient, performant, and financially optimized regardless of operational complexity.
Defining Strategic Operations Management
The Core Operational Structure
Strategic operations management functions as the foundational architecture that coordinates engineering velocity with fiscal responsibility. At its core, this discipline relies on an open data loop that feeds infrastructure telemetry directly into financial analysis engines. The system constantly ingests metrics from various endpoints, aggregates the data by business unit, and compares actual expenditure against predefined budgets.
| Operational Layer | Core Data Input | Automated Output Action |
| Telemetry Ingestion | Real-time CPU, Memory, and Network I/O logs | Dynamic data streaming to optimization engines |
| Financial Allocation | Resource tags, cost center codes, department metadata | Automated metadata verification and tag enforcement |
| Policy Enforcement | Budget thresholds, utilization baselines, scheduling rules | Immediate rightsizing and autonomous resource termination |
This structural flow ensures that financial visibility is never delayed by manual accounting cycles. Instead, the operational architecture processes utilization data continuously, allowing the system to execute real-time adjustments. By maintaining this tight integration between data pipelines and infrastructure state, organizations eliminate billing surprises entirely.
Daily Tasks of Systems Coordinators
Systems coordinators and financial engineers spend their days managing the software pipelines that govern cloud infrastructure. Instead of manually reviewing spreadsheets, these specialists build and maintain automated policy engines that audit resource environments. They continuously write, test, and deploy code that defines how the infrastructure must react to changing traffic patterns and budget limits.
- Configuring Autonomous Scheduling: Writing rules that automatically shut down non-production environments during weekends and non-business hours.
- Auditing Tagging Compliance: Deploying automated scripts that instantly detect and quarantine any cloud resource lacking a valid cost-center tag.
- Managing Spot Instance Pools: Building failover mechanisms that safely transition workloads from expensive on-demand servers to low-cost spot instances.
- Analyzing Rightsizing Metrics: Reviewing systemic recommendations to adjust underutilized database clusters and storage volumes down to optimal performance tiers.
Localized Control vs. Broad System Architecture
Managing modern systems requires balancing highly granular component tracking against the macro-level multi-system infrastructure architecture. Localized control focuses entirely on individual applications, microservices, or specific database instances. Engineers working at this level optimize the exact parameters of a single service to ensure it runs efficiently without consuming excess memory or compute power.
Conversely, broad system architecture requires analyzing how hundreds of interconnected services interact financially across the entire global footprint. An automated change made to a single localized service can cause unexpected data transfer costs across different cloud regions. Therefore, strategic management systems must maintain comprehensive visibility, ensuring that local optimization efforts do not accidentally drive up expenses elsewhere in the broader ecosystem.
The Efficiency Mindset
Transitioning to automated financial operations requires a profound cultural shift that prioritizes long-term system stability and efficiency over raw feature output. Historically, software teams focused exclusively on delivery speed, treating infrastructure costs as a secondary problem for accounting teams to handle. The efficiency mindset redefines waste as a critical systemic vulnerability that directly threatens organizational agility.
When teams embrace this engineering philosophy, they treat cloud cost optimization as a core non-functional requirement alongside security and performance. Engineers take pride in building elegant, lean architectures that maximize the business value generated by every single unit of compute power. This cultural transformation ensures that financial responsibility becomes a shared, continuous engineering practice rather than a painful quarterly audit.
The 7 Core Principles of Automated Cloud Financial Engineering
1. Embracing Risk and Managing Variability
Modern distributed systems are inherently volatile, making absolute perfection an impossible and prohibitively expensive goal to chase. Automated financial engineering explicitly embraces this variability by design, focusing on managing acceptable systemic risk rather than attempting to eliminate it entirely. Teams intentionally accept minor, short-term performance variances if those variances yield massive, long-term financial savings for the organization.
By programming infrastructure to tolerate controlled resource constraints, engineers run workloads much closer to their actual utilization limits. This strategy involves setting up dynamic buffers that can absorb sudden traffic surges without permanently over-provisioning infrastructure. Accepting this managed risk allows systems to operate at peak financial efficiency while maintaining acceptable service delivery standards.
2. Establishing Service Level Objectives (SLOs)
To balance infrastructure cost with application performance, engineering teams must establish clear, data-driven Service Level Objectives. These measurable targets define the exact boundaries of acceptable systemic success from the perspective of the end user. For example, a team might specify that ninety-nine percent of database queries must return a response within two hundred milliseconds.
[System Performance Metrics] ──► [Service Level Objectives (SLOs)] ──► [Automated Infrastructure Scaler]
│
Balances Performance with Cloud Spend ◄┘
Once these performance boundaries are codified, automation engines utilize them to drive infrastructure scaling and resource allocation decisions. If the system safely meets its performance objectives, the automation engine can aggressively downsize resources to minimize cloud spend. This clear alignment prevents organizations from over-paying for excessive performance levels that provide no noticeable benefit to the user experience.
3. Eliminating Toil and Manual Processes
Manual cost tracking, spreadsheet reconciliation, and human resource auditing represent pure operational toil that severely restricts organizational velocity. Financial engineering focuses heavily on identifying these repetitive, manual processes and writing software to engineer them away permanently. If a human engineer must manually log into a console every Friday to turn off development servers, that process is a prime candidate for automation.
Eliminating this toil frees up valuable engineering talent to focus on building high-impact architecture and better optimization algorithms. Furthermore, software-driven policy enforcement operates flawlessly twenty-four hours a day, entirely eliminating the human errors that lead to costly configuration mistakes. Removing manual friction ensures that cost-saving policies are executed instantly, consistently, and at massive scale.
4. Monitoring & Observability Across the Pipeline
You cannot optimize what you cannot see, which makes comprehensive observability across the entire deployment pipeline absolutely vital. Modern optimization systems require real-time, granular visibility into every virtual asset, container, data pipeline, and third-party software integration. This data collection process relies on open-source agents and monitoring daemons that continuously stream performance telemetry into centralized dashboards.
This continuous visibility prevents financial blind spots where abandoned projects or unmapped resources quietly generate massive ongoing expenses. Advanced monitoring tools correlate infrastructure metrics directly with business data, such as calculating the exact cloud cost incurred per user login. This deep contextual insight allows organizations to make highly informed, strategic adjustments to their operational architecture.
5. Automation Over Manual Coordination
Relying on manual cross-department coordination to approve infrastructure changes creates severe operational bottlenecks and guarantees human errors. Instead, modern financial engineering prioritizes programmatic automation to govern resource life cycles through sophisticated software control loops. When a cost threshold is crossed, the system executes pre-approved programmatic playbooks to remediate the issue instantly.
For example, rather than emailing an engineering lead to request resource rightsizing, an automated system directly modifies the configuration file. It can automatically downgrade an over-provisioned staging database during low-traffic periods and restore it before business hours resume. This rapid, automated response mechanism keeps infrastructure precisely aligned with actual real-time business demands.
6. Release Engineering and Deployment Stability
Consistent, predictable, and highly stable application delivery pipelines form the backbone of effective cloud cost optimization. When deployment processes are chaotic or prone to failure, teams inevitably over-provision resources as an emergency safety net. Integrating automated financial checks directly into continuous integration and deployment channels ensures that every update is fully optimized before it ever hits production.
[Code Commit] ──► [CI/CD Pipeline with Financial Checks] ──► [Automated Cost Simulation] ──► [Safe, Optimized Deployment]
These automated pipelines can run cost simulation models on infrastructure-as-code files to predict precisely how a deployment will impact the monthly bill. If the code introduces modifications that exceed financial guardrails, the pipeline automatically pauses the release for engineering review. This proactive gatekeeping prevents inefficient, costly architectural patterns from ever leaking into live production environments.
7. Simplicity in Network Architecture
Complex, convoluted network architectures featuring redundant data paths and chaotic routing rules directly cause massive, unexpected cloud data transfer fees. Automated financial engineering strongly emphasizes maintaining clean, minimal, and highly simplified network environments to minimize these hidden operational expenses. Keeping network structures clean directly reduces the total failure surface area while making cost attribution incredibly straightforward.
Automated tools can map network topologies in real time, exposing expensive data transfers across different cloud availability zones or regions. By consolidating resources and optimizing data routing paths, software teams eliminate unnecessary network hops and transit charges. This focus on architectural simplicity dramatically improves overall system performance while keeping network expenditures highly predictable.
Key Operational Concepts You Must Know
SLA vs. SLO vs. SLI — Explained Simply
Understanding cloud financial operations requires mastering the precise distinctions between Service Level Agreements, Objectives, and Indicators. These three metrics form the core framework that teams use to balance infrastructure reliability with total operational expenditure.
- Service Level Agreement (SLA): The formal, legally binding commitment made to end users, defining the financial penalties or refunds triggered if system performance drops below an acceptable standard.
- Service Level Objective (SLO): The strict internal target that engineering teams shoot for to ensure the system stays well clear of breaking the legal agreement.
- Service Level Indicator (SLI): The specific, real-time metric that measures the current performance of a system, such as tracking the exact percentage of successful API requests over a rolling window.
Error Budgets — The Game Changer for Operational Risk
An error budget represents the exact amount of system unreliability that an organization is willing to tolerate over a specific timeframe. Calculated directly from the internal objective, it defines the margin between perfect uptime and the minimum acceptable performance baseline. For instance, if your service target is ninety-nine percent uptime, your error budget allows for exactly one percent of total downtime.
This concept completely transforms operational risk management by serving as a clear architectural traffic light for development teams. As long as the error budget remains green and healthy, engineers can aggressively ship features and deploy cost-saving automation policies. However, if a series of system outages burns through the budget, all feature deployments freeze, and engineering focus shifts entirely to stabilizing system reliability.
Toil — The Silent Productivity Killer in Infrastructure
Toil refers to repetitive, manual, and non-creative tasks that are directly tied to running a production service but scale linearly with system growth. Examples include manually cleaning out full server disk drives, resetting stuck user accounts, or manually copying configuration data between environments. Toil provides no long-term structural value to an organization and actively pulls engineering talent away from high-impact innovation.
[System Scale Increases] ──► [Manual Labor (Toil) Increases Linearly] ──► [Engineering Burnout & Stagnation]
│
[Must be Engineered Away with Automation] ◄──────────┘
Financial engineering departments calculate toil metrics meticulously to justify building automated software alternatives. If a team spends twenty hours every week manually adjusting database capacities, that labor cost is tracked as an operational loss. Writing code to handle those adjustments automatically eliminates that ongoing labor expense and allows the organization to scale without expanding headcount.
Incident Management & Postmortems
When unexpected system failures or cost anomalies occur, modern organizations utilize blameless postmortem workflows to analyze the event objectively. A blameless culture assumes that engineers operate with good intentions and that failures stem from weak systemic guardrails rather than individual carelessness. Instead of pointing fingers, teams focus on conducting a thorough root cause analysis to uncover the underlying architectural flaws.
The final output of this process is a detailed postmortem document that outlines exactly why the failure happened and lists concrete engineering tasks to prevent a recurrence. For instance, if an automated script mistakenly deleted a critical storage volume, the postmortem would focus on improving the script’s validation logic. This continuous learning cycle ensures that production incidents ultimately drive long-term structural resilience and operational maturity.
Capacity Planning
Capacity planning is the proactive process of forecasting future resource requirements to ensure infrastructure can handle upcoming demand spikes without over-provisioning. Historically, this task relied on crude guesswork and static spreadsheets created by managers once or twice a year. In automated environments, capacity planning runs continuously using sophisticated statistical models and historical utilization data.
Automated planning tools analyze long-term traffic trends, seasonal purchase spikes, and business growth metrics to project infrastructure needs months in advance. This data allows organizations to make highly strategic cloud commitments, such as purchasing long-term reservations for predictable, baseline workloads. Consequently, teams secure deep structural discounts from cloud vendors while maintaining sufficient elasticity to absorb unexpected usage surges.
The Four Golden Signals of Pipeline Performance
To maintain absolute control over distributed microservices, engineers continuously monitor the four golden signals of system performance. These metrics provide immediate, actionable insights into the operational health, efficiency, and financial consumption of any cloud application.
- Latency: The precise time it takes for a system to process a specific service request, allowing teams to isolate performance bottlenecks instantly.
- Traffic: A direct measure of total system demand, tracking metrics like concurrent user sessions, network packets per second, or incoming API requests.
- Errors: The total rate of requests that fail explicitly, return incorrect data, or time out entirely before processing completes.
- Saturation: A metric defining exactly how full a system’s core resources are, exposing critical constraints in CPU, memory, or disk storage capacity.
Platform Implementation vs. Culture — What’s the Real Difference?
The Philosophy Difference
Implementing automated cloud optimization requires balancing technical platform engineering with an overarching organizational culture. The cultural philosophy focuses entirely on human alignment, shared accountability, and breaking down traditional communication silos between finance and engineering departments. It establishes the core organizational values, guiding principles, and open communication channels required to make financial efficiency a shared priority.
Conversely, platform implementation represents the concrete engineering mechanics, software code, and automated tooling used to enforce those cultural values. Culture defines why the organization must eliminate cloud waste, while the platform provides the technical infrastructure to execute that goal programmatically. Relying on culture alone results in well-intentioned discussions without any real reduction in cloud spend, while deploying tools without culture leads to engineer resistance.
Roles & Responsibilities Compared
To understand how these two areas operate on a daily basis, it helps to examine the specific responsibilities across different organizational disciplines.
- Culture & FinOps Practitioners:
- Fostering open communication and collaboration between finance professionals, product owners, and engineering leaders.
- Establishing clear cost-allocation models, managing cloud provider enterprise discounts, and setting high-level corporate budgets.
- Educating development teams on the financial impact of their architectural decisions and celebrating cost-saving milestones.
- Platform & Infrastructure Engineers:
- Building, maintaining, and scaling the internal automated developer platforms and continuous deployment pipelines.
- Writing infrastructure-as-code templates, creating automated rightsizing policies, and deploying real-time telemetry collectors.
- Constructing the automated guardrails that prevent unconfigured or untagged resources from entering production environments.
Can You Have Both Disciplines?
Modern, high-performing technology enterprises do not choose between these two approaches; rather, they intentionally integrate both into a unified operational strategy. Cultural initiatives build the trust and organizational buy-in required to deploy strict, automated platform guardrails without causing internal friction. When engineers understand the financial strategy, they gladly adopt the automated optimization tools provided by the platform team.
┌────────────────────────────────────────┐
│ FinOps Cultural Alignment │
│ (Shared Responsibility & Education) │
└───────────────────┬────────────────────┘
│ Informs & Guides
▼
┌────────────────────────────────────────┐
│ Platform Automation Engines │
│ (Strict Guardrails & Auto-scaling) │
└────────────────────────────────────────┘
This combination creates a powerful, self-reinforcing loop within the organization. The culture establishes the high-level efficiency goals, while the platform engineering team delivers the software systems to meet those goals automatically. This alignment ensures that cost optimization remains a continuous, frictionless aspect of the standard software development lifecycle.
Which One Should Your Team Adopt?
The exact balance between cultural initiatives and platform engineering depends heavily on your organization’s size and engineering maturity level. Small, early-stage startups should prioritize building an efficiency culture first, as their lean teams can align quickly without complex automation systems. In these environments, establishing basic tagging habits and cost awareness across the team is usually sufficient to control early cloud expenditures.
For large global enterprises operating massive, distributed cloud footprints, relying purely on cultural buy-in is entirely insufficient. These organizations must invest heavily in building robust, automated developer platforms that actively enforce financial policies across thousands of services. The platform must act as an objective, automated safety net, ensuring that cloud infrastructure remains highly optimized regardless of individual human diligence.
Real-World Use Cases of Modern Operations
How Tech Leaders Use Operational Metrics
Major global tech enterprises utilize advanced telemetry frameworks to tie infrastructure metrics directly to real-time financial reporting systems. For instance, large streaming networks do not simply look at total monthly compute costs in isolation. Instead, they track highly contextual metrics like the exact infrastructure cost incurred per hour of video streamed to a user.
This granular insight allows product managers to analyze the true profitability of specific platform features and make highly strategic architectural adjustments. If a new user recommendation algorithm increases compute costs by forty percent but only drives a one percent increase in user engagement, the system flags the variance. This clear data allows teams to retire inefficient features before they cause substantial financial damage.
Chaos Engineering Approaches to Resilient Systems
Top-tier technology firms utilize chaos engineering methodologies to proactively test both the reliability and financial resilience of their infrastructure. Engineers intentionally inject controlled failures into live production environments, such as terminating random server clusters or simulating cross-region network outages. These exercises expose hidden infrastructure dependencies and verify that automated failover mechanisms operate exactly as designed.
[Inject Controlled Failure] ──► [Monitor System Telemetry] ──► [Verify Auto-Recovery] ──► [Harden Infrastructure]
From a financial perspective, chaos engineering verifies that automated auto-scaling systems contract correctly once an artificial traffic surge concludes. It ensures that backup systems do not remain running indefinitely at peak costs after an outage has been fully resolved. This proactive verification process hardens the infrastructure, making it incredibly lean, reliable, and highly cost-efficient under pressure.
Handling Reliability at Massive Scale
Global software platforms serving millions of concurrent users handle massive traffic spikes by using intelligent, multi-cloud container orchestration frameworks. These systems utilize predictive scheduling algorithms to scale container clusters up or down ahead of anticipated user traffic patterns. By precisely matching resource capacity with real-time user demand, these platforms completely eliminate the need for permanent, expensive infrastructure buffers.
Additionally, these scale architectures leverage automated workload shifting to run non-critical data processing tasks in cloud regions where electricity and compute prices are lowest at that specific hour. This dynamic allocation strategy allows massive enterprises to maximize hardware utilization rates while maintaining flawless application performance. The result is a highly resilient global footprint that operates at the lowest possible price point.
High-Availability in Fintech Operations
Financial technology platforms operate under zero-tolerance mandates for system downtime, requiring absolute continuous availability for payment processing systems. To balance this extreme reliability requirement with strict cost controls, fintech infrastructure engineers deploy multi-layered, automated redundancy strategies. They utilize highly dynamic containerized clusters that can shift transactional traffic across different cloud zones in milliseconds if an outage occurs.
To avoid paying for idle backup hardware, these platforms use sophisticated automation to keep secondary disaster-recovery systems in a scaled-down, minimal state. The system constantly monitors transactional health indicators, and if a primary zone shows signs of failure, the automation engine scales up the recovery zone instantly. This approach guarantees flawless transaction delivery while saving millions of dollars annually in idle infrastructure costs.
Scaled-Down but Essential Systems for Startups
Early-stage startups with limited venture funding apply these exact same automation principles, but scale them down to minimize operational overhead. Instead of building custom optimization software, they rely on lightweight, open-source cron scripts and built-in cloud provider budgeting alerts. These simple automations ensure that non-essential development and testing environments are completely shut down overnight and during weekends.
[Start of Business Day] ──► [Automated Script Spins Up Dev Servers]
[End of Business Day] ──► [Automated Script Powers Down Dev Servers to Save 60% Cost]
Startups also utilize automated serverless computing architectures, where infrastructure costs are generated only when a customer actively triggers a line of code. This architectural choice aligns cloud expenditures directly with early customer traction, completely eliminating baseline server maintenance costs. Applying these fundamental efficiency principles early allows lean startup teams to extend their financial runway significantly.
Common Mistakes in Operations Engineering
Mistake 1 — Confusing System Management with Just Being On-Call
A frequent and costly error organizations make is treating cloud financial operations as a reactive, manual task assigned to an on-call engineering team. When teams operate under this flawed assumption, they spend their time chasing alerts and manually cleaning up cost overruns after the billing cycle ends. This approach treats cost management as a stressful cleaning chore rather than a core engineering discipline.
True automated financial operations focus on building proactive software systems that prevent cost anomalies from ever occurring in the first place. It involves writing automated policy engines, configuring clean auto-scaling rules, and embedding cost guardrails directly into the deployment pipeline. Moving away from reactive manual intervention allows organizations to maintain continuous efficiency without burning out their engineering teams.
Mistake 2 — Setting Unrealistic SLOs
Many engineering teams mistakenly demand perfect one hundred percent uptime for non-critical software applications when setting up their operational targets. Chasing this level of reliability requires building highly complex, deeply redundant infrastructure architectures that drive cloud expenditures up exponentially. Furthermore, maintaining these extreme environments requires constant manual oversight and slows feature deployment velocity to an absolute crawl.
[Demand 100% Uptime] ──► [Exponential Cloud Cost Increase] + [Development Speed Stalls]
[Set Realistic SLOs] ──► [Optimized Cloud Expenditure] + [Rapid Innovation Velocity]
Organizations must realize that every additional decimal point of uptime target requires a massive financial investment that rarely translates to increased user satisfaction. Teams should carefully analyze actual user expectations to establish realistic objectives that properly balance application performance with cloud expenditures. This pragmatic approach keeps infrastructure lean and preserves the engineering velocity needed to ship innovative features.
Mistake 3 — Ignoring Toil Until It’s Too Late
Neglecting to track and systematically eliminate manual operational toil allows substantial technical and financial debt to quietly accumulate within an organization. When infrastructure engineers spend their days manually verifying cloud invoices, adjusting server sizes, and cleaning data volumes, systemic innovation stalls completely. Over time, this repetitive manual work creates severe operational bottlenecks that block the organization’s ability to scale efficiently.
To avoid this trap, management teams must explicitly treat manual toil as a costly systemic bug that requires immediate software remediation. Engineers must be given dedicated time to design, write, and deploy automation scripts that handle these repetitive tasks completely hands-free. Eliminating manual friction keeps engineering teams focused on high-value optimization projects that drive long-term structural efficiency.
Mistake 4 — Skipping Blameless Postmortems
When a severe cost anomaly or unexpected system outage occurs, organizations often default to a culture of blame, seeking an individual to hold accountable. This toxic reaction causes engineering teams to actively hide mistakes, cover up architectural inefficiencies, and resist sharing data across departments. Consequently, the underlying structural flaws remain unaddressed, guaranteeing that the exact same failure will happen again.
Skipping deep, blameless postmortem analysis prevents an organization from turning operational failures into valuable learning opportunities and structural improvements. Teams must establish a safe environment focused entirely on discovering why the system’s automated guardrails failed to catch the issue. This transparency allows engineers to build stronger, more resilient programmatic checks that permanently protect the business from future financial shocks.
Mistake 5 — Monitoring Without Actionable Alerts
Deploying hundreds of monitoring dashboards that flood engineering communication channels with non-actionable notifications creates severe alert fatigue. When engineers receive dozens of low-priority cost warnings every day, they quickly learn to ignore the notifications entirely. Consequently, when a genuine, critical financial emergency occurs, the alert is buried in the noise, resulting in delayed response times and massive waste.
| Notification Quality | Alert Trigger Condition | Engineering Team Action |
| Ineffective / Noisy | Minor, temporary CPU spike on a non-critical dev server | Ignored or muted completely, creating dangerous alert fatigue |
| Critical / Actionable | Production database spending increases 200% in one hour | Immediate execution of an automated rollback script |
Every automated alert configured in your monitoring environment must be tied directly to a clear, documented, and actionable engineering playbook. If a notification does not require an immediate, specific modification to the infrastructure, it should be demoted to a passive report. Filtering out operational noise ensures that engineering attention remains focused on critical systemic issues that demand rapid remediation.
Mistake 6 — Not Involving Operational Engineers in the Design Phase
Organizations frequently make the mistake of excluding infrastructure and financial engineers from initial software architecture design discussions. Product teams often design complex applications in isolation, focusing exclusively on user features without considering the eventual cloud infrastructure costs. When these unoptimized designs are thrown over the wall to operations teams, hosting them in production becomes prohibitively expensive.
Attempting to re-engineer or fix an inefficient cloud architecture after it has already been fully deployed is an incredibly slow and costly endeavor. Operational and financial specialists must be embedded into the product design lifecycle from day one to evaluate the financial feasibility of new systems. This proactive collaboration ensures that applications are architected from the very beginning to leverage cost-effective, automated cloud scaling patterns.
Essential Infrastructure Tools & Technologies
Monitoring & Observability
Maintaining complete financial control over complex, distributed systems requires a robust collection of open-source and commercial observability tools. Platforms like Prometheus and Grafana form the foundation of open-source monitoring, allowing teams to collect and visualize high-resolution system performance data. Commercial solutions such as Datadog and New Relic provide advanced application performance monitoring, tracing data requests across complex microservices. These systems ingest massive telemetry streams, allowing engineers to correlate infrastructure utilization directly with real-time cloud provider billing data.
Incident Management
When critical cost anomalies or sudden system outages break through operational guardrails, teams rely on automated incident management platforms to coordinate responses. Tools like PagerDuty ingest alert streams from monitoring systems and use intelligent routing rules to escalate issues to the correct on-call engineer. These platforms centralize communication channels, document incident timelines, and automatically trigger pre-configured remediation playbooks to stabilize the environment. Using automated incident routing eliminates manual coordination delays, ensuring that expensive operational failures are resolved in minutes rather than hours.
CI/CD & Release Engineering
Integrating financial policies directly into the software delivery pipeline requires powerful continuous integration and continuous deployment automation engines. Jenkins serves as a highly flexible, open-source automation server used to run compliance checks and cost-simulation scripts during code compilation. Modern GitOps delivery tools like Argo CD and Spinnaker automate application deployments to cloud-native clusters, ensuring production environments match intended configurations exactly. These tools allow platform teams to embed automated budget checks into the deployment lifecycle, stopping inefficient code configurations before they reach live production.
[Code Repository] ──► [Jenkins: Financial Audit] ──► [Argo CD: GitOps Deployment] ──► [Optimized Production Cluster]
Chaos Engineering
To proactively test infrastructure resilience and verify that cost-saving auto-scaling policies operate perfectly under stress, teams utilize specialized chaos engineering software. Tools like Chaos Monkey inject controlled, random failures into live production environments, such as safely terminating server instances or degrading network speeds. These exercises force infrastructure automation engines to adapt to chaotic conditions, proving that failover systems execute correctly without generating permanent cloud waste. Embracing controlled chaos allows engineering teams to identify hidden vulnerabilities, optimize auto-scaling parameters, and build deep confidence in their automated recovery systems.
SLO Management
Tracking real-time system performance against defined service objectives requires specialized reliability management platforms that calculate error budgets continuously. Platforms like Nobl9 integrate directly with existing monitoring tools to ingest performance metrics and evaluate them against agreed user thresholds. These systems provide clear, centralized visibility into error budget consumption rates, alerting teams when an infrastructure modification threatens long-term stability. Using dedicated objective management software allows organizations to make objective, data-driven decisions that perfectly balance rapid feature development with cloud cost constraints.
How to Become an Operations Expert — Career Roadmap
Skills Every Specialist Must Have
Building a successful career in automated cloud financial operations requires mastering a diverse blend of software development, systems administration, and financial data analysis. Individuals must possess deep expertise in navigating terminal environments and writing automated scripting languages like Python, Bash, or Go to build custom optimization tools. Furthermore, a comprehensive understanding of cloud networking architectures, container orchestration, and declarative infrastructure-as-code platforms is absolutely essential.
Beyond pure technical engineering capabilities, modern specialists must develop strong financial literacy and data analysis skills. You must learn to interpret complex cloud billing records, build granular cost-allocation models, and translate technical utilization metrics into clear business insights. Mastering this unique intersection of engineering velocity and financial precision allows specialists to solve complex architectural challenges that directly improve organizational profitability.
The Professional Learning Path
The educational journey toward becoming a senior infrastructure specialist begins with mastering the fundamentals of system administration and local environment configurations. Aspiring professionals should focus on deploying simple web applications, managing local databases, and writing basic automation scripts to handle routine maintenance tasks. Once comfortable with local environments, the next logical step involves transitioning workloads to major public cloud platforms to explore virtualized networking and basic scaling mechanics.
[Level 1: System Admin Basics] ──► [Level 2: Cloud Infrastructure] ──► [Level 3: Distributed Microservices] ──► [Level 4: Enterprise FinOps Architect]
After establishing a solid cloud foundation, learning path progression requires diving deeply into distributed container orchestration frameworks like Kubernetes. You must master how to configure horizontal autoscalers, manage multi-tenant cluster resources, and deploy centralized monitoring pipelines to track application performance. Finally, professionals combine these technical skills with corporate accounting principles, moving into senior architectural roles that design automated, enterprise-wide financial optimization systems.
Certifications Worth Pursuing
Validating your technical expertise and cloud infrastructure knowledge requires earning industry-recognized professional certifications that showcase your ability to manage complex enterprise environments. Aspiring specialists should pursue foundational cloud architecture credentials from major cloud vendors to demonstrate their baseline engineering competencies. Additionally, earning specialized certifications in container orchestration proves your ability to manage highly dynamic, cloud-native application environments at scale.
To solidify your expertise in the financial management domain, earning credentials from specialized industry organizations is highly recommended. These focused certifications validate your deep understanding of cost-allocation methodologies, cloud procurement strategies, and automated optimization frameworks. Holding a combination of core engineering and dedicated financial management credentials makes professionals highly competitive candidates for senior enterprise infrastructure roles.
Educational Resources with [PROVIDER_NAME]
Navigating the rapidly evolving landscape of cloud financial engineering requires access to high-quality, up-to-date educational materials and professional mentorship. The comprehensive training courses and hands-on laboratory exercises offered by Finopsschool provide the perfect structured environment to master these advanced operational strategies. Their industry-expert led curriculum covers everything from basic cost allocation patterns to deploying highly sophisticated, automated rightsizing pipelines across multi-cloud environments.
By engaging with their specialized educational content, you will gain practical, real-world experience configuring standard monitoring tools, managing error budgets, and building automated financial guardrails. Their professional learning community connects you with a global network of engineering peers and senior mentors who share valuable operational insights and career advancement strategies. Investing in structured education ensures you develop the cutting-edge technical capabilities required to lead enterprise-wide financial optimization initiatives successfully.
The Future of Systems Management
AI and Automation in System Optimization
The integration of machine learning models and artificial intelligence is completely revolutionizing how modern organizations optimize their cloud infrastructure footprints. Traditional optimization engines rely on static, human-written rules that trigger rightsizing actions only after a utilization threshold is crossed. Advanced AI-driven analytics systems analyze massive historical telemetry data streams to predict upcoming traffic spikes and resource requirements hours before they happen.
These intelligent systems automatically identify highly subtle anomaly patterns, isolate hidden performance bottlenecks, and execute precise root cause analysis without manual intervention. By constantly learning from infrastructure behavior, machine intelligence optimizes resource allocation parameters far more accurately than human engineers ever could. This transition to predictive, autonomous system optimization allows enterprises to eliminate infrastructure waste entirely while ensuring flawless application availability.
Platform Engineering — The Evolution of Infrastructure
Platform engineering represents a major structural shift in how modern enterprises design, build, and deliver infrastructure capabilities to internal software developers. Instead of requiring individual developers to manually configure complex cloud resources, platform teams construct unified, self-service internal developer platforms. These centralized platforms expose clean, standardized templates that automatically embed organizational security protocols, compliance frameworks, and financial guardrails by default.
[Software Developer] ──► [Internal Developer Platform (IDP)] ──► [Automated Deployment with Built-in FinOps Guardrails]
This self-service model dramatically reduces operational friction, allowing development teams to spin up fully compliant application environments in seconds. Because the platform’s automated backend handles resource scaling and financial optimization behind the scenes, developers can focus exclusively on writing product features. This evolutionary pattern treats infrastructure as a polished product, significantly increasing organizational velocity while ensuring strict, continuous cost controls.
Management in Cloud-Native & Kubernetes Environments
As organizations accelerate their migration toward highly dynamic, containerized Kubernetes architectures, managing infrastructure costs introduces unique operational orchestration challenges. In multi-tenant container environments, multiple business units and microservices share the same underlying pool of physical cloud hardware servers. This shared infrastructure makes traditional, high-level cloud billing attribution models completely ineffective for accurate cost tracking.
Future systems management frameworks must leverage deep container-level telemetry tools to measure the exact resource consumption of individual application microservices. Automated control loops must operate at the container level, continuously adjusting resource limits, managing cluster scaling parameters, and scheduling non-critical workloads dynamically. Masterfully navigating these complex cloud-native architectures allows modern enterprises to maintain granular financial visibility and operational efficiency across massive distributed footprints.
Operational Skills That Will Matter Most
The ongoing evolution of distributed cloud infrastructure is fundamentally redefining the specific technical skills and professional competencies required to excel as a system specialist. Aspiring experts must move beyond traditional systems administration habits and focus heavily on developing advanced programmatic automation capabilities. The ability to treat infrastructure entirely as software code and build robust, automated developer platforms will become the baseline requirement for future roles.
Additionally, professionals must cultivate deep data observability expertise and strong financial acumen to successfully connect technical performance with corporate business outcomes. Specialists who can accurately interpret massive data streams, design intelligent auto-scaling systems, and implement automated cloud cost-management frameworks will see extraordinary market demand. Prioritizing these modern operational disciplines ensures software engineers remain invaluable assets capable of driving long-term organizational growth and architectural resilience.
FAQ Section
- What is the primary role of automation within a cloud financial management framework?Automation systematically eliminates manual cost-tracking overhead by using software-driven policies, real-time metric analysis, and programmatic guardrails to manage cloud spend continuously. It monitors infrastructure performance signals to execute instant rightsizing, enforce resource tagging compliance, and terminate idle assets without requiring slow, manual human intervention.
- How do internal developer platforms support organizational cost-management strategies?Internal developer platforms expose standardized, self-service infrastructure templates that automatically embed pre-approved configuration parameters, security rules, and financial guardrails. This structural pattern allows software development teams to safely provision optimized resources independently while ensuring all deployments conform to corporate efficiency standards.
- What is the operational difference between a Service Level Objective and an Error Budget?A Service Level Objective defines the specific, measurable performance target that a system must maintain to ensure customer satisfaction. An Error Budget represents the mathematical inverse of that target, outlining the exact amount of acceptable system downtime or performance degradation an organization tolerates before feature releases freeze.
- Why is traditional manual capacity planning ineffective in modern cloud environments?Traditional planning relies on slow guesswork and static spreadsheets, which inevitably forces teams to over-provision massive infrastructure buffers to handle potential demand spikes safely. Modern cloud environments change in milliseconds, requiring automated, data-driven forecasting systems that continuously analyze real-time usage telemetry to optimize capacity commitments dynamically.
- How does a blameless postmortem culture improve long-term system infrastructure reliability?A blameless postmortem culture assumes that failures stem from weak systemic guardrails rather than individual human carelessness, encouraging engineering teams to document operational mistakes transparently. This open environment allows specialists to conduct thorough root cause analyses and design robust, automated software checks that permanently prevent identical failures from recurring.
- What fundamental technical skills should an engineer focus on to become a FinOps specialist?Engineers must master core terminal navigation, programmatic scripting languages like Python or Go, container orchestration frameworks, and declarative infrastructure-as-code platforms. Additionally, they must develop strong financial data literacy to interpret complex cloud billing records and connect technical resource utilization metrics directly with business profitability.
Final Summary
Maintaining continuous, long-term health across complex distributed systems requires moving away from reactive, manual intervention and embracing automated, software-driven management architectures. By feeding real-time infrastructure telemetry directly into intelligent optimization engines, organizations systematically eliminate structural waste while ensuring flawless application availability. This comprehensive operational approach balances development velocity with fiscal responsibility, transforming cloud cost management from a painful accounting chore into an automated engineering practice.
The future of technology infrastructure belongs to organizations that successfully treat efficiency as a primary non-functional software metric embedded directly into their delivery pipelines. Implementing robust developer platforms, establishing data-driven service objectives, and fostering a collaborative corporate culture ensures that scaling operations remains highly predictable and performant. To position your organization at the absolute cutting edge of this technical evolution, leverage the specialized professional educational courses available at Finopsschool to establish long-term structural resilience and financial stability.