Imagine waking up to a sudden infrastructure bill that completely drains your quarterly budget due to an unmonitored cloud resource spike. This exact bottleneck paralyzes hundreds of expanding corporate teams because they spin up environments without tracking real financial accountability. Consequently, organizations lose millions of dollars yearly simply because engineering speed remains entirely disconnected from fiscal governance. To solve this critical operational failure, forward-thinking enterprises deploy structured cloud financial management systems that align engineering, finance, and technology leadership toward shared financial accountability.
Therefore, establishing clear frameworks around cloud spending ensures that teams balance business velocity with strict cost optimization. This comprehensive guide details the precise strategies, operational structural changes, and core metrics required to build a sustainable fiscal cloud framework. By reading further, your teams will master the exact architecture needed to optimize resource allocation, manage error budgets, and eliminate cloud waste permanently. You can master these advanced frameworks easily by exploring the professional training tracks at Finopsschool, which provides structured roadmaps to transform your corporate cloud culture into a lean, value-driven engine.
The Origin of Systems Infrastructure
The Early Industrial Bottlenecks
Traditional enterprise IT architectures heavily relied on fixed, on-premise hardware environments that required immense capital expenditure. Because engineering teams operated in deep isolation from financial departments, developers provisioned computing resources based on absolute peak capacity estimates. This structural silo meant that expensive servers sat entirely idle for major parts of the fiscal year. Furthermore, procurement cycles took months to execute, creating massive operational delays and halting software release momentum. Finance teams viewed technology departments purely as a cost center, while engineers viewed procurement processes as a frustrating bureaucratic hurdle.
Moving Toward Unified Workflow Automation
As cloud technology emerged, organizations suddenly shifted from predictable capital expenses to completely variable operational expenditures. However, this architectural transition quickly introduced severe challenges because engineers could now spin up infinite resources with a single API call. Without centralized automation frameworks or spending visibility, cloud bills escalated entirely out of control. Consequently, progressive organizations realized they needed a unified system to blend cost consciousness with automated continuous deployment workflows. This cultural integration established a new paradigm where resource management, engineering velocity, and budgetary guardrails operated inside a single continuous loop.
Global Expansion Across Commercial Ecosystems
Today, this unified financial and operational philosophy scales rapidly across large-scale global enterprises and multi-cloud environments. Modern commercial ecosystems require absolute cloud agility, yet they cannot afford unmonitored resource sprawl. As a result, global organizations establish dedicated financial operations practices to centralize visibility and decentralize execution. This strategic expansion allows distributed teams to retain their cloud deployment speed while maintaining complete alignment with corporate profitability goals. Ultimately, managing cloud environments through a unified financial lens has transformed from a niche startup trick into a foundational requirement for global market survival.
Defining Strategic Operations Management
The Core Operational Structure
The operational architecture of a modern cloud financial system depends entirely on a cross-functional loop involving engineering, finance, and product management. Specifically, data flows continuously from cloud infrastructure APIs directly into centralized analytics dashboards to provide real-time cost visibility. This structural framework relies heavily on rigorous resource tagging metadata, which maps every single virtual asset to a specific business unit. Consequently, the organization can track financial accountability down to the exact microservice level. This continuous feedback cycle empowers teams to analyze data instantly, make real-time alterations, and keep expenditures fully aligned with corporate financial baselines.
Daily Tasks of Systems Coordinators
Systems coordinators and financial operations specialists spend their days monitoring live utilization anomalies to prevent sudden budget overruns. For instance, these practitioners examine automated alert logs to isolate abandoned storage volumes or unutilized staging environments. They also collaborate directly with software engineers to resize over-provisioned infrastructure assets according to actual operational demand. Additionally, these coordinators review commitment-based discount opportunities, such as reserved instances or savings plans, to secure maximum baseline discounts from cloud providers. They continuously translate complex cloud billing data into clear, actionable architectural recommendations for engineering squads.
Localized Control vs. Broad System Architecture
Managing specialized cloud resources requires a delicate balance between localized development freedom and global architecture guardrails. On one hand, localized control allows individual development teams to choose specific cloud services to accelerate feature delivery. On the other hand, broad system architecture ensures that these choices conform to enterprise-wide spending policies and security baselines. Therefore, a successful operational model establishes strict centralized governance policies while utilizing automated self-service platforms for local resource provisioning. This dual approach ensures that localized engineering agility never undermines the overarching financial stability of the entire global enterprise.
The Efficiency Mindset
Transitioning to a modern cloud financial model requires a massive cultural shift that prioritizes systemic efficiency over raw resource abundance. Historically, engineers focused solely on system performance and uptime, completely ignoring the underlying financial consequences of their architectural designs. To build a sustainable framework, organizations must cultivate an efficiency mindset where cost is treated as a core architectural metric. This means that a highly optimized, cost-effective infrastructure is celebrated just as much as a high-speed software feature release. When teams embrace this cultural philosophy, long-term system stability and financial predictability naturally become foundational elements of the development lifecycle.
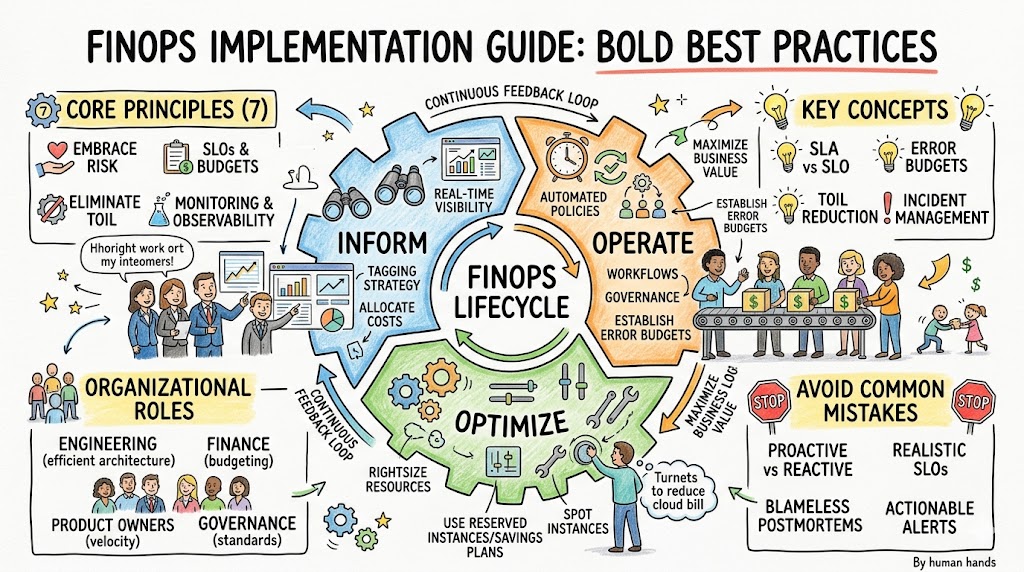
The 7 Core Principles of FinOps
1. Embracing Risk and Managing Variability
Cloud environments are inherently dynamic, meaning that spending patterns will naturally fluctuate based on user traffic and business demands. Therefore, attempting to enforce rigid, immovable legacy budgets will only stifle innovation and break application scalability. Instead of fearing this variability, modern teams embrace it by building flexible operational frameworks that adapt to changing workloads. The core objective is not to minimize spending to absolute zero, but rather to ensure that every dollar spent correlates directly with business growth. By managing acceptable financial and systemic risk, organizations maximize their agility while keeping waste entirely within acceptable boundaries.
2. Establishing Service Level Objectives (SLOs)
To balance financial performance with system reliability, cross-functional teams must collaborate to establish clear, measurable targets for systemic success. These Service Level Objectives determine the exact performance boundaries that an application must maintain to keep users satisfied. Crucially, setting these targets requires a direct conversation about cost, since aiming for perfect uptime drastically escalates infrastructure expenses. By defining clear boundaries around performance and cost, teams can make informed decisions about where to invest resources. Ultimately, SLOs serve as the baseline metric that keeps engineering velocity, user satisfaction, and cloud spending in perfect equilibrium.
3. Eliminating Toil and Manual Processes
Manual resource tracking and spreadsheet-driven cost auditing represent significant operational toil that slows down enterprise momentum. Consequently, engineering teams must focus on identifying these repetitive, manual cost-management tasks and eliminating them through automated code solutions. For example, manual cleanup of old container images or manual scheduling of non-production environments should be replaced by automated governance scripts. By engineering away these tedious tasks, organizations free up valuable developer time for high-impact architecture optimization. Eliminating operational toil ensures that your cost management practices scale efficiently without requiring massive human overhead.
4. Monitoring & Observability Across the Pipeline
Complete financial visibility across the entire deployment environment prevents costly blind spots and eliminates unexpected billing surprises. Therefore, organizations must implement deep observability solutions that connect raw infrastructure performance data with real-time billing metrics. This comprehensive monitoring strategy allows teams to view the exact financial impact of an application deployment within minutes of execution. Furthermore, observability tools help engineers discover underutilized assets, inefficient database queries, and architectural bottlenecks that drive up cloud bills. Maintaining a clear, real-time view across the pipeline ensures that teams resolve anomalies before they transform into major financial crises.
5. Automation Over Manual Coordination
Scaling modern enterprise workflows requires an automated engineering approach to policy enforcement rather than relying on manual human coordination. When a cloud system detects an unutilized resource or an egregious budget violation, automated systems should flag or remediate the issue instantly. For instance, automated governance tools can shut down non-essential testing environments outside of standard business hours without human intervention. This strategy reduces reliance on manual reminders, ensuring that corporate cost-optimization policies are applied uniformly across all departments. Utilizing smart software solutions to enforce guardrails preserves engineering speed while guaranteeing strict adherence to fiscal limits.
6. Release Engineering and Deployment Stability
Predictable, consistent, and safe infrastructure delivery strategies are essential for maintaining both system uptime and financial budget stability. When application releases are erratic or poorly tested, they frequently introduce architectural bugs that cause massive cloud resource leaks. Therefore, implementing mature release engineering practices, such as canary deployments or blue-green infrastructure patterns, helps teams monitor resource usage in small increments. If a new update causes an unexpected spike in processing consumption or costs, automated rollback systems immediately restore the previous stable state. This disciplined approach minimizes financial exposure while ensuring continuous application availability.
7. Simplicity in Network Architecture
Keeping cloud environments minimal and cleanly structured directly reduces the complex failure surfaces that cause financial and technical waste. Intricate, overlapping multi-region network configurations frequently generate massive hidden data transfer fees that surprise financial teams. By deliberately designing simple, clean data paths and localized microservice communications, organizations eliminate unnecessary cross-zone networking charges. Furthermore, simple architectures are significantly easier for engineering teams to monitor, troubleshoot, and optimize over time. Embracing architectural simplicity saves immediate infrastructure costs while drastically improving the long-term reliability and maintainability of the enterprise cloud.
Key Operational Concepts You Must Know
SLA vs. SLO vs. SLI — Explained Simply
Understanding the precise distinctions between these three reliability metrics is vital for balancing cloud performance with organizational budget goals.
- Service Level Agreement (SLA): The formal, legally binding commitment made directly to external end-users, defining the financial penalties or refunds if system performance drops below acceptable thresholds.
- Service Level Objective (SLO): The internal target metric that engineering teams aim to achieve to ensure the system safely satisfies the public SLA.
- Service Level Indicator (SLI): The specific, real-time quantitative measure of system performance, such as latency or error rate, that tracks compliance against the established SLO.
Error Budgets — The Game Changer for Operational Risk
An error budget represents the exact amount of system unreliability that an organization is willing to tolerate over a specific fiscal period. Calculated mathematically as $100\% – \text{SLO}$, this concept acts as a dynamic mechanism to balance architectural innovation with baseline system safety. When a development team possesses a full, unused error budget, they can aggressively deploy new features and experiment with cloud architectures. However, if the error budget is entirely exhausted due to frequent system outages or cost overruns, feature releases freeze immediately. During this freeze, engineering focus shifts completely toward system stabilization, optimization, and debt reduction.
Toil — The Silent Productivity Killer in Infrastructure
Toil refers to repetitive, manual, operational tasks that lack long-term strategic value and scale linearly as infrastructure expands. Examples include manually resetting cloud service accounts, copying data across billing spreadsheets, or manually approving minor cost exceptions. If left unaddressed, accumulation of toil completely destroys engineering velocity and leads to severe team burnout. To eliminate this issue, teams must systematically calculate the hours wasted on manual interventions and build automated software workflows to replace them. Turning operational tasks into automated, self-healing code pathways ensures infrastructure scales smoothly without inflating headcount costs.
Incident Management & Postmortems
When a system failure or a massive cloud cost anomaly occurs, teams must activate structured incident management procedures immediately. Following the resolution of the immediate crisis, the organization must conduct a completely blameless postmortem analysis. The fundamental goal of a blameless culture is to isolate the systemic flaws that allowed the incident to happen, rather than pointing fingers at individual developers. By analyzing root causes openly, teams can implement permanent architectural fixes, update automated alerts, and share critical lessons across the company. This progressive approach turns operational failures into valuable learning opportunities that strengthen systemic resilience.
Capacity Planning
Capacity planning is the proactive engineering practice of forecasting future business growth and preparing cloud infrastructure ahead of actual consumer demand spikes. Rather than simply over-provisioning infrastructure arbitrarily, modern teams leverage historical utilization patterns and predictive data analytics to forecast requirements. This strategy ensures that the organization secures deep volume discounts through long-term cloud provider commitments well before infrastructure scale-up occurs. Additionally, automated scaling policies are carefully tuned to handle temporary traffic surges without creating permanent resource waste. Accurate capacity planning guarantees continuous application availability while avoiding sudden, unbudgeted capital expenditures.
The Four Golden Signals of Pipeline Performance
To maintain deep visibility into system performance and its associated costs, infrastructure teams must trace the four golden signals:
- Latency: The total time it takes for a system to process a specific request, ensuring performance remains crisp.
- Traffic: The overall demand being placed on the network infrastructure, measured in requests per second or concurrent users.
- Errors: The rate of requests that fail systematically across the deployment pipeline, indicating underlying code or resource issues.
- Saturation: The fraction of total system resources being utilized, highlighting exactly when infrastructure components are reaching maximum capacity limits.
Platform Implementation vs. Culture — What’s the Real Difference?
The Philosophy Difference
Implementing automated software tools is straightforward, but transforming underlying corporate behavior requires deep cultural realignment. Specifically, platform implementation focuses entirely on deploying software dashboards, setting up automated tagging scripts, and generating cost reports. Conversely, cultural transformation centers on shifting human behavior so that every developer considers cost during the initial design phase. Without a supportive corporate culture, advanced cost management platforms are ignored, leading to continued infrastructure waste. Therefore, organizations must treat tools as basic enablers and focus heavily on driving accountability across every engineering squad.
Roles & Responsibilities Compared
To understand how these concepts operate across a mature enterprise, we can examine the specific day-to-day responsibilities of different departments.
- Engineering Teams: Focus on designing efficient, scalable system architectures, implementing automated resource tagging, and executing right-sizing recommendations.
- Finance Departments: Manage enterprise-wide budget forecasting, track overall cloud expenditures against corporate targets, and analyze long-term commitment discounts.
- Product Owners: Prioritize cost-optimization tasks inside the software delivery backlog and balance feature velocity against running infrastructure costs.
- Central Governance Teams: Establish global cloud architecture standards, evaluate enterprise tooling options, and coordinate cross-functional educational workshops.
Can You Have Both Disciplines?
Modern high-growth enterprises absolutely must integrate both technical platforms and cultural frameworks to achieve sustainable cloud optimization. Tools provide the raw data and automation capabilities, while culture provides the human motivation to act on that information. When these two areas align, engineers utilize automated software to optimize workloads naturally as part of their standard deployment workflows. Furthermore, finance teams leverage these automated systems to gain absolute clarity into future spending vectors without disrupting software release schedules. Blending these disciplines converts cost management from a friction-filled auditing process into a seamless operational advantage.
Which One Should Your Team Adopt?
Choosing where to focus your initial organizational energy depends heavily on your current engineering maturity and team size.
| Criteria | Cultural Framework Focus | Tooling & Platform Focus |
| Best For | Small startups building initial cloud workflows | Large enterprises managing multi-cloud sprawl |
| Primary Goal | Instilling spending accountability in developers | Centralizing visibility across separate business units |
| Execution Method | Open communication, shared KPIs, and education | Deploying automated tagging and anomaly detection software |
| Immediate Benefit | Prevents wasteful architectural habits early | Instantly uncovers hidden infrastructure leaks |
Real-World Use Cases of Modern Operations
How Tech Leaders Use Operational Metrics
Major global software enterprises track real-time unit economics to ensure that cloud costs scale proportionally with business value. For example, a leading streaming platform measures the exact infrastructure cost required to deliver one hour of video content to a user. By tracking this granular metric, engineering teams can determine whether a recent software update improved or degraded architectural efficiency. This operational focus allows technology executives to forecast cloud spending accurately based on direct user growth projections. Consequently, corporate budgeting transitions from an uneducated guessing game into an exact, data-driven science.
Chaos Engineering Approaches to Resilient Systems
Top-tier technology teams utilize chaos engineering tools to intentionally inject controlled faults into production environments to uncover hidden infrastructure flaws. For instance, engineers deliberately take down entire cloud zones or simulate severe network latency to witness how automated failover systems respond. Crucially, these controlled disruptions also uncover hidden financial risks, such as automated scaling loops that spin up infinite expensive backup servers needlessly. By discovering these systemic and financial vulnerabilities during daylight hours, teams can reconfigure automation guardrails safely. Chaos engineering builds ultimate infrastructure resilience while preventing catastrophic, unexpected billing anomalies.
Handling Reliability at Massive Scale
Distributed microservices handling millions of concurrent global transactions require dynamic, automated scaling solutions that adjust perfectly to live utilization demands. A premier global e-commerce enterprise handles massive shopping traffic spikes by leveraging automated container orchestration systems that scale clusters up and down instantly. To prevent massive waste, these clusters utilize spot instances—surplus cloud compute capacity available at steep discounts—for non-critical workloads. This strategy requires advanced container scheduling policies that shift workloads instantly if spot capacity becomes unavailable. Mastering this architectural pattern enables massive global scale while keeping infrastructure budgets perfectly optimized.
High-Availability in Fintech Operations
Financial technology systems operate within strict, zero-tolerance frameworks regarding application downtime and data processing errors. For example, payment processing platforms require continuous high-availability architectures across multiple separate cloud zones to guarantee uninterrupted transaction flows. To achieve this safely without inflating infrastructure costs, fintech engineers utilize automated serverless architectures that charge purely per transaction executed. Furthermore, strict data archiving automated policies migrate older transaction records to low-cost deep storage tiers automatically based on strict regulatory timeframes. This ensures continuous, audit-ready compliance while keeping production database running costs highly optimized.
Scaled-Down but Essential Systems for Startups
Early-stage startups do not possess the massive financial budgets of global corporations, making early cost optimization absolutely vital for survival. Therefore, small engineering teams apply core cloud efficiency principles by implementing basic, high-impact automation rules from day one. For example, a startup can deploy simple open-source scripts that automatically pause all development servers during weekends and evening hours. Additionally, they establish basic budget alerts that notify founders via chat applications the moment spending crosses a minimal baseline threshold. These lightweight operational steps preserve critical runway while instilling a permanent culture of financial responsibility.
Common Mistakes in Operations Engineering
Mistake 1 — Confusing System Management with Just Being On-Call
Many organizations mistakenly believe they have implemented a mature infrastructure practice simply by putting their engineers on a rotational on-call schedule. This approach fails completely because true operational engineering centers on proactive software architecture design rather than reactive fire-fighting. When developers spend their entire shift merely responding to alerts, they accumulate massive amounts of technical and operational debt. Proactive specialists focus on writing automated code that prevents outages and cost anomalies from ever occurring in the first place. Shifting from a reactive mindset to a proactive engineering model is essential for long-term cloud success.
Mistake 2 — Setting Unrealistic SLOs
Demanding perfect 100% uptime for an application is an architectural mistake that stalls software feature delivery and causes extreme engineering burnout. Achieving extreme levels of availability requires building hyper-redundant infrastructure arrays, which causes cloud expenditures to escalate exponentially. Furthermore, maintaining an unrealistic target means teams spend all their time tweaking stability instead of launching valuable new business features. Organizations must analyze actual user satisfaction levels to establish realistic performance targets that keep customers happy without overspending on infrastructure. Setting rational objectives protects your financial budgets while maintaining continuous development momentum.
Mistake 3 — Ignoring Toil Until It’s Late
Allowing manual, repetitive administrative tasks to accumulate unaddressed blocks software delivery velocity and inflates engineering operational costs significantly. When development teams spend half their working week manually cleaning up old cloud resources or correcting billing errors, innovation halts completely. This accumulation of operational debt creates severe process bottlenecks and causes top-tier engineering talent to leave due to sheer frustration. Leadership must explicitly allocate specific engineering sprint cycles to build automated scripts that systematically eliminate manual toil. Prioritizing continuous automation keeps the deployment pipeline lean, efficient, and fully scalable.
Mistake 4 — Skipping Blameless Postmortems
When an organization responds to a system failure or cost overrun by hunting for a human scapegoat, they severely damage company culture. In a punitive environment, engineers actively hide mistakes, cover up architectural flaws, and avoid experimenting with innovative cost-saving designs. Skipping deep systemic analysis means the underlying root cause remains uncorrected, guaranteeing that the same failure will repeat eventually. Teams must embrace a blameless postmortem philosophy that focuses entirely on fixing fragile systems rather than punishing individual people. Openly discussing failures creates a transparent culture where infrastructure resilience improves continuously.
Mistake 5 — Monitoring Without Actionable Alerts
Flooding engineering communication channels with a continuous stream of low-priority notification warnings creates severe alert fatigue across the organization. When engineers receive hundreds of un-actionable cost notifications every day, they quickly learn to ignore all incoming alerts completely. Consequently, critical alerts detailing massive live cloud cost leaks go completely unnoticed until the final monthly bill arrives. To prevent this danger, every automated alert must be tied directly to a specific, well-documented operational response procedure. If an alert does not require immediate, concrete human intervention, it should be logged quietly to a dashboard rather than paging an engineer.
Mistake 6 — Not Involving Operational Engineers in the Design Phase
Treating infrastructure deployment as an afterthought by excluding operational and financial experts from initial software design meetings introduces severe inefficiencies. When software developers build applications in a vacuum, they frequently choose cloud databases or architecture patterns that are incredibly expensive to scale in production. Rectifying these structural mistakes after an application has launched requires massive, complex code rewrites that delay business timelines. Involving cloud financial specialists and operational engineers from the very first design whiteboard session ensures that efficiency is baked into the code. Upfront collaboration saves massive amounts of development time and prevents structural cost overruns.
Essential Infrastructure Tools & Technologies
Monitoring & Observability
Maintaining complete control over a dynamic cloud environment requires a robust suite of observability tools to track live performance metrics. Standard enterprise tools such as Prometheus, Grafana, Datadog, and New Relic enable teams to gather deep telemetry across all layers of infrastructure. Specifically, these platforms allow engineers to build customized dashboards that display application response times alongside real-time cost accumulations. This integration helps developers instantly see how specific code modifications impact memory usage and overall cloud infrastructure spend. Maintaining deep visibility ensures that your cloud infrastructure remains fully performant and highly cost-efficient.
Incident Management
When unexpected outages or severe cloud budget anomalies occur, teams rely on dedicated incident management platforms to coordinate rapid responses. Solutions like PagerDuty orchestrate on-call engineer schedules, ensuring that the right technical expert is paged instantly when specific thresholds break. These platforms integrate directly with monitoring systems to suppress duplicate alerts and provide critical context regarding the systemic failure surface. By utilizing automated incident routing, organizations dramatically reduce their mean time to resolution during critical production operational crises. Streamlining communication workflows minimizes downtime and prevents localized infrastructure errors from snowballing into corporate financial disasters.
CI/CD & Release Engineering
Automating the software delivery pipeline requires powerful continuous integration and continuous deployment engines to test and deploy infrastructure updates smoothly. Tools like Jenkins, Spinnaker, and Argo CD enable engineering teams to deliver application code changes safely via automated GitOps workflows. These automation frameworks ensure that every infrastructure modification undergoes strict automated testing and cost validation before entering live production. By managing cloud resources as version-controlled code, organizations guarantee that their deployments remain fully repeatable, transparent, and secure. Mature deployment automation minimizes manual human intervention, accelerating feature velocity while preserving absolute infrastructure stability.
Chaos Engineering
Injecting controlled failures into a production cloud environment safely requires specialized software designed to uncover hidden infrastructure weaknesses. Chaos Monkey, originally developed by major streaming enterprises, serves as a premier tool for randomly terminating cloud compute instances. This continuous, controlled disruption forces engineering teams to build self-healing, highly redundant architectures that recover automatically from individual component losses. By intentionally testing system resilience during normal working hours, organizations eliminate unexpected single points of failure before they impact global users. Utilizing chaos tools transforms system reliability from an academic theory into a practical, battle-tested reality.
SLO Management
Tracking real-time infrastructure performance against agreed customer thresholds requires specialized platforms focused on Service Level Objective lifecycle management. Tools like Nobl9 help engineering teams aggregate telemetry data from multiple monitoring sources to calculate error budgets accurately. These platforms provide clear visibility into how rapidly an application is consuming its allowed unreliability allocation during feature rollouts. Consequently, product managers can make data-backed decisions on whether to accelerate feature releases or pivot engineering focus toward optimization. Utilizing dedicated metric tracking software keeps cross-functional teams aligned around objective, user-centric reliability goals.
How to Become an Operations Expert — Career Roadmap
Skills Every Specialist Must Have
Entering this highly specialized domain requires a robust combination of software engineering capabilities and deep financial analytical skills. First, professionals must master command-line interfaces, shell scripting, and infrastructure-as-code automation frameworks to manage cloud systems programmatically. Second, acquiring a deep understanding of cloud pricing models, billing APIs, and data transfer dynamics across major vendors is absolutely essential. Finally, specialists must become experts in core data manipulation techniques, allowing them to extract actionable insights from massive billing data sets. Combining deep technical infrastructure expertise with sharp financial literacy makes you an invaluable asset to any modern technology organization.
The Professional Learning Path
Building expertise in this field follows a structured, step-by-step educational progression that starts with foundational systems management. Initially, a practitioner should focus on mastering basic cloud provisioning, networking configurations, and containerization principles using local testing environments. Following this phase, the learning path expands into deploying advanced continuous deployment automation pipelines and multi-region microservice architectures. Next, professionals must study the strategic business aspects of technology management, including corporate procurement cycles, forecasting methodologies, and budget allocation. This comprehensive educational journey transforms a traditional technical engineer into a strategic architectural leader capable of managing massive corporate cloud ecosystems.
Certifications Worth Pursuing
Validating your advanced technical skills and financial management expertise requires earning industry-recognized credentials that are highly respected by global employers. Professionals should actively pursue certifications from major cloud providers, focusing on advanced solution architect and DevOps engineer tracks. Additionally, achieving specialized credentials from the FinOps Foundation, such as the Certified Practitioner or Certified Architect designations, adds immense career value. These professional certifications prove to prospective employers that you possess the practical skills to architect highly efficient cloud systems. Investing in targeted professional credentials accelerates your career trajectory and unlocks senior leadership roles within global technology organizations.
Educational Resources with FinOpsSchool
Aspiring cloud financial leaders can drastically accelerate their learning curve by leveraging the comprehensive courses and professional study tracks available at FinOpsSchool. The institution provides deep-dive educational modules designed by seasoned industry practitioners who manage multi-million dollar cloud budgets daily. Students gain valuable hands-on experience through real-world simulation labs, practicing advanced cost allocation, anomaly detection, and automated right-sizing strategies. Furthermore, the platform offers vibrant community forums where students can network with global technology peers and share modern operational insights. Exploring these structured learning programs equips your teams with the exact skills needed to eliminate enterprise cloud waste.
The Future of Systems Management
AI and Automation in System Optimization
The upcoming evolution of cloud optimization relies heavily on integrating advanced machine learning models directly into operational deployment pipelines. Traditional static alert rules are quickly being replaced by intelligent anomaly detection systems that understand complex historical spending patterns. These AI-driven systems isolate minor resource leaks and predictive budget overruns long before a human analyst can review the raw logs. Furthermore, autonomous optimization systems will soon modify cloud infrastructure configurations in real time based on predictive user traffic patterns. Embracing machine intelligence allows organizations to optimize resource consumption dynamically, shifting from reactive analysis to fully autonomous cost governance.
Platform Engineering — The Evolution of Infrastructure
Platform engineering represents a major shift in modern corporate environments, focusing on building internal self-service developer portals that abstract infrastructure complexity. Instead of forcing software developers to navigate intricate cloud billing policies manually, these centralized platforms bake financial compliance directly into templates. For example, a developer can spin up a pre-configured database environment that automatically includes optimization rules, tracking tags, and automated shutdown schedules. This strategy eliminates operational friction, allowing software squads to ship features quickly while ensuring complete adherence to corporate cost guardrails. Building secure internal platforms ensures enterprise efficiency scales naturally without slowing down development speed.
Management in Cloud-Native & Kubernetes Environments
As organizations migrate heavily toward containerized, dynamic multi-cloud clusters, tracking financial accountability introduces highly complex architectural challenges. Traditional billing models struggle to allocate costs accurately when hundreds of separate microservices share a single large Kubernetes cluster. Therefore, the future of infrastructure management requires utilizing advanced open-source cost allocation tools designed specifically for container environments. These specialized systems analyze exact CPU and memory utilization per container namespace, allowing finance departments to assign costs accurately to individual teams. Mastering container resource management guarantees that your cloud-native architectures remain lean, transparent, and fully optimized.
Operational Skills That Will Matter Most
The technical landscape is shifting rapidly, meaning that future systems professionals must cultivate a highly versatile skill set to remain competitive. Specifically, raw technical infrastructure management is becoming secondary to advanced data analytics, unit economics modeling, and cross-functional corporate communication. Future leaders must possess the ability to translate complex cloud metrics into clear profitability business data for executive boardrooms. Additionally, mastering sustainable green computing metrics and optimization for carbon footprint reductions will soon become a mandatory enterprise requirement. Developing this blended expertise ensures you remain an invaluable strategic partner in guiding your organization’s digital transformation journey.
FAQ Section
- What is the typical career trajectory for a specialist entering this infrastructure domain?Professionals usually begin their journey as cloud engineers or financial analysts before transitioning into dedicated optimization roles. Over time, they advance into senior systems coordinators, principal platform architects, and eventually executive director roles managing global enterprise infrastructure strategy.
- How do these modern efficiency practices differ from traditional IT budget management?Traditional budgeting relies on static, annual capital forecasts and rigid procurement cycles handled exclusively by finance departments. In contrast, modern cloud financial management operates as a continuous, real-time loop where cross-functional engineering teams share immediate accountability for variable daily cloud expenditures.
- What are the average salary expectations for certified professionals in this field?Due to the massive global demand for cloud cost optimization expertise, certified specialists command highly lucrative compensation packages. Mid-level practitioners typically earn significant six-figure salaries, while senior architects and global practice leads secure premium executive compensation across major technology hubs.
- Which cloud platform is the most challenging to monitor for infrastructure waste?Every major cloud vendor presents unique optimization challenges due to highly complex, specialized pricing structures and data transfer fees. Multi-cloud environments introduce the highest difficulty, requiring centralized observability tools to normalize separate billing data streams into a single source of truth.
- How often should an organization audit its resource tags and allocation metadata?Resource tagging audits must operate as a continuous, automated validation process inside the deployment pipeline rather than a manual periodic check. Automated governance scripts should scan your environment daily, instantly alerting or isolating any resource that lacks proper cost-center metadata.
- Can small startups benefit from these methodologies without hiring a dedicated team?Startups absolutely benefit by embedding these efficiency principles directly into their foundational engineering culture from day one. Instead of hiring a separate dedicated team, early-stage companies leverage lightweight automation tools and simple budget alerts to keep their infrastructure lean and runway extended.
Final Summary
Establishing a mature financial operations practice is a transformative journey that aligns engineering agility with strict corporate fiscal responsibility. By implementing clear observability frameworks, defining rational performance targets, and systematically eliminating manual toil, organizations build highly resilient, cost-effective ecosystems. Ultimately, managing cloud infrastructure efficiently is not about cutting corners or slowing down innovation, but rather about maximizing the business value delivered per dollar spent. Embracing these core structural changes converts cloud cost management from a frustrating operational bottleneck into an evergreen competitive advantage. As technology environments expand globally, building an automated, efficiency-driven infrastructure culture with [Finopsschool] ensures your enterprise scales sustainably, securely, and profitably into the future.