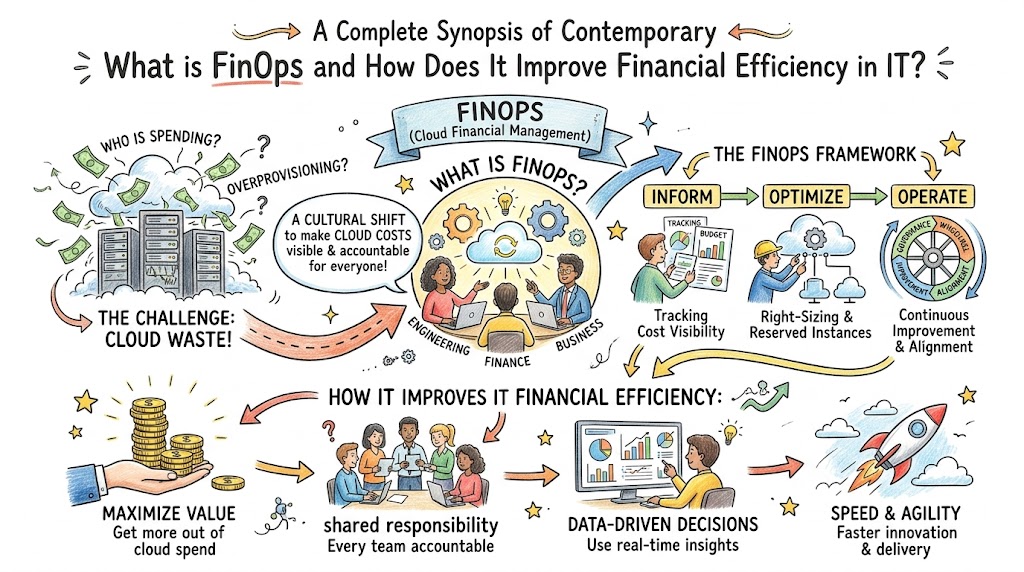
Imagine an unmonitored cloud architecture running complex compute workloads that suddenly spins out of fiscal control overnight. This exact operational bottleneck terrifies modern engineering leaders because uncontrolled public cloud consumption drains corporate capital faster than legacy hardware deployments ever could. When engineering teams build systems without financial guardrails, cloud bills explode unexpectedly, creating massive organizational friction and stalling software deployment velocities. Consequently, organizations must find a structured framework that bridges the deep gap between infrastructure engineering performance and corporate fiscal accountability.
FinOps introduces an operational blueprint that changes how companies manage their digital cloud infrastructure by treating financial management as a continuous engineering discipline. This comprehensive methodology unites technology specialists, finance directors, and business teams to foster shared financial responsibility across every cloud environment. By establishing real-time data visibility, teams optimize cloud costs while maintaining maximum system performance and software delivery speeds. Therefore, embracing this framework allows growing modern enterprises to scale their digital architectures efficiently without experiencing sudden budget overruns.
If your engineering team wants to master these advanced cost-optimization strategies and build resilient architectures, you must choose the right training partner. You can master cloud financial management by enrolling in the structured technical courses offered directly through Finopsschool. Their expert-led curriculum gives you the exact hands-on experience and real-world tools needed to drive financial efficiency across multi-cloud environments. Let us begin by analyzing where infrastructure management started and how modern workflows became automated.
The Origin of Systems Infrastructure
The Early Industrial Bottlenecks
Traditional technology operations suffered from deep institutional divides that consistently slowed down product delivery pipelines and increased capital expenses. In legacy enterprise setups, development teams focused exclusively on shipping new features quickly, while separate operations teams kept systems stable. This structural separation created immense friction because engineers did not understand the underlying hardware costs or operational limitations of their software. Consequently, deployments frequently failed, debugging took weeks, and infrastructure budgets bloated because teams over-provisioned physical hardware to avoid system downtime.
Moving Toward Unified Workflow Automation
The introduction of cloud computing and automated infrastructure provisioning altered the baseline dynamics of corporate technology ecosystems. As virtualized environments replaced physical hardware, engineering teams learned to define complex infrastructure configurations completely through software code. This technical shift broke down traditional organizational silos, allowing teams to collaborate on deployment pipelines, security policies, and architectural stability. Therefore, unified workflow automation emerged as a standard practice, allowing modern enterprises to deploy software rapidly while tracking operational health automatically.
Global Expansion Across Commercial Ecosystems
Automated operational frameworks quickly spread from pioneer web companies into large-scale commercial tech enterprises around the world. Organizations realized that manually managing thousands of distributed servers was completely unsustainable and cost-prohibitive over long-term growth cycles. As a result, companies across global banking, e-commerce, and logistics sectors adopted standardized automation patterns to manage their expanding cloud footprints. This global expansion created a brand-new marketplace demand for specialized engineers who could optimize complex systems while controlling infrastructure budgets.
Defining Strategic Operations Management
The Core Operational Structure
Strategic operations management requires a structured architectural framework that treats system infrastructure as an evolving software application. Instead of manually configuring individual cloud servers, specialists use automated pipelines to deploy, monitor, and scale distributed system components. Real-time metrics flow from live application nodes directly back into central telemetry dashboards, giving engineers immediate visibility into system health. This continuous loop ensures that any performance degradation or unexpected cost spike triggers automated remediation before it impacts end users.
Daily Tasks of Systems Coordinators
Systems coordinators spend their workdays building automated infrastructure tools rather than manually triaging repetitive system alerts. These specialists write clean automation code, configure deployment pipelines, optimize cloud resource allocations, and conduct comprehensive architectural reviews. They also collaborate closely with product developers to ensure new application services meet strict reliability, security, and cost-efficiency standards. When an unexpected system failure happens, they coordinate the technical response, stabilize the active environment, and investigate the root cause.
Localized Control vs. Broad System Architecture
Managing modern technology infrastructure requires balancing granular component monitoring with high-level multi-system architectural orchestration. Localized control focuses on specific metrics like a single database instance’s memory utilization or an isolated microservice container’s response latency. Conversely, broad system architecture tracking looks at how hundreds of interconnected services communicate across multiple global cloud availability zones. Engineers must master both perspectives, ensuring individual application nodes run efficiently while keeping the entire distributed platform resilient and stable.
The Efficiency Mindset
Shifting to an automation-first culture requires a fundamental evolution in how engineering teams view system stability and operational costs. Rather than simply reacting to infrastructure outages, teams adopt a proactive mindset focused on long-term architecture reliability and resource optimization. Engineers intentionally design systems to handle unexpected cloud infrastructure failures gracefully through automated self-healing mechanisms and dynamic resource scaling. This continuous focus on architectural efficiency reduces manual firefighting, eliminates wasted cloud spend, and allows businesses to scale operations smoothly.
The 7 Core Principles of What is FinOps and How Does It Improve Financial Efficiency in IT?
1. Embracing Risk and Managing Variability
Building a completely flawless, zero-downtime distributed system remains an impossible and financially ruinous goal for modern digital businesses. Therefore, engineering teams must accept a controlled amount of systemic risk and learn to manage variable cloud workloads effectively. Instead of spending millions of dollars trying to achieve perfect uptime, companies define acceptable failure rates that do not harm user satisfaction. This practical approach allows teams to launch new software features rapidly while keeping cloud infrastructure costs balanced.
2. Establishing Service Level Objectives (SLOs)
Teams must establish clear, data-driven targets that define what acceptable system performance looks like from the end-user’s perspective. These measurable milestones ensure that engineering decisions, product roadmaps, and budget allocations align directly with actual business requirements. By tracking real-time performance against these precise metrics, teams avoid over-engineering systems or over-spending on unnecessary cloud resources. Consequently, service level objectives serve as the primary operational compass for balancing system reliability with software development velocity.
3. Eliminating Toil and Manual Processes
Toil consists of repetitive, mundane, and manual tasks that do not add long-term strategic value to an enterprise’s infrastructure. Modern operations focus on identifying these operational bottlenecks and using smart software code to engineer them away completely. Automating routine tasks like server patching, database backups, and resource provisioning frees up valuable engineering time for strategic work. As a result, organizations reduce human error, accelerate operational workflows, and lower overall operational overhead.
4. Monitoring & Observability Across the Pipeline
Complete visibility across every stage of the software deployment and infrastructure pipeline prevents dangerous system blind spots. Modern observability platforms gather deep telemetry data, including granular system metrics, distributed execution traces, and structured application logs. This continuous stream of operational intelligence helps engineers pinpoint hidden performance bottlenecks and discover unexpected cloud cost anomalies instantly. Therefore, robust monitoring ensures that teams maintain total control over both system health and operational budgets simultaneously.
5. Automation Over Manual Coordination
Scaling modern multi-cloud environments requires replacing manual human intervention with intelligent, programmatic infrastructure management solutions. When systems experience unexpected spikes in user traffic, automated scaling policies dynamically provision additional cloud resources to handle the load. Conversely, when demand drops, the infrastructure automatically scales down to prevent companies from paying for idle computing power. This automation-first strategy ensures optimal system availability while keeping infrastructure asset expenditures lean and highly efficient.
6. Release Engineering and Deployment Stability
Consistent, predictable, and safe software deployment practices are absolutely essential for maintaining large-scale digital platform stability. Teams utilize advanced deployment techniques like canary releases and blue-green deployments to roll out software changes to small user segments safely. If a new software version introduces a performance bug or increases resource costs, deployment engines automatically roll back the change. This disciplined release strategy minimizes user disruptions and protects production environments from unexpected operational instabilities.
7. Simplicity in Network Architecture
Keeping cloud infrastructure and network configurations clean, minimalist, and transparent directly reduces an enterprise’s total failure surface area. Complex, tangled architectures make it incredibly difficult for engineers to debug system outrages or accurately track cloud expenditure origins. By designing modular, simple architectures, teams ensure that data flows efficiently and cloud resource ownership stays completely transparent. This structural simplicity speeds up system troubleshooting, simplifies financial auditing, and improves overall platform security.
Key Operational Concepts You Must Know
SLA vs. SLO vs. SLI — Explained Simply
Understanding the exact distinctions between these three metrics keeps your engineering, finance, and legal teams fully aligned.
- Service Level Agreement (SLA): A formal, legally binding contract between a service provider and users detailing performance commitments and financial penalties for failures.
- Service Level Objective (SLO): A target reliability metric defined by internal engineering teams to maintain acceptable system performance.
- Service Level Indicator (SLI): A precise, real-time measurement showing the actual performance of a specific system component at any given moment.
Error Budgets — The Game Changer for Operational Risk
An error budget represents the exact amount of system downtime or performance degradation an application can safely tolerate before violating its SLO. For instance, if your system objective requires 99.9% uptime, your corresponding error budget allows for exactly 0.1% downtime. Product development teams use this budget to deploy innovative features rapidly as long as the budget remains positive. However, if unexpected infrastructure failures consume the budget, teams must halt new features and focus exclusively on system stabilization.
Toil — The Silent Productivity Killer in Infrastructure
Toil acts as a silent drain on engineering velocity, pulling specialists away from innovation and toward repetitive maintenance. To identify toil, look for manual tasks that are highly repetitive, easily automatable, and grow linearly with system scale. Teams calculate the exact percentage of engineering time spent on these tasks and track it closely on operational dashboards. By enforcing strict limits on manual work, organizations compel engineers to build automation scripts that eliminate these operational drains.
Incident Management & Postmortems
When severe system outages occur, modern organizations rely on structured, blameless incident management workflows to restore services quickly. After resolving the immediate issue, engineering teams conduct a comprehensive blameless postmortem to identify the true root cause. This methodology focuses entirely on discovering structural system weaknesses rather than pointing fingers or punishing individual engineers. Documenting these lessons prevents similar failures from happening again and continuously strengthens the reliability of the entire infrastructure.
Capacity Planning
Proactive capacity planning helps businesses forecast future infrastructure growth demands while avoiding expensive, unnecessary over-provisioning of cloud resources. Engineers analyze historic system usage trends, seasonal traffic spikes, and upcoming product launches to estimate computing requirements accurately. This data-driven forecasting allows companies to purchase cloud reservations early, securing significant financial discounts from major cloud service providers. Consequently, effective capacity planning ensures that systems scale smoothly ahead of customer demand while keeping corporate infrastructure costs predictable.
The Four Golden Signals of Pipeline Performance
To maintain complete operational control over distributed architectures, teams must constantly monitor the four golden signals of performance:
- Latency: The exact time it takes for a system to process a specific user request successfully.
- Traffic: A direct measurement of total demand being placed on the infrastructure, such as HTTP requests per second.
- Errors: The rate of incoming user requests that fail due to internal system bugs or configuration issues.
- Saturation: A metric showing how close a system resource, like CPU or memory, is to reaching its maximum capacity.
Platform Implementation vs. Culture — What’s the Real Difference?
The Philosophy Difference
Many organizations struggle to understand whether modern operations require a technical platform implementation or a deep cultural philosophy shift. A platform implementation focuses primarily on deploying advanced software tools, configuring real-time telemetry dashboards, and writing infrastructure automation scripts. On the other hand, the cultural philosophy concentrates on breaking down team silos, embracing shared operational responsibility, and accepting controlled systemic risks. True operational excellence requires combining both elements, using smart software platforms to support a transparent, data-driven engineering culture.
Roles & Responsibilities Compared
Understanding how different tech specialties handle daily infrastructure duties clarifies organizational structures.
| Technical Specialization | Focus Area | Primary Daily Responsibility |
| Platform Engineering | Internal Developer Tools | Building self-service deployment portals and automated infrastructure templates for software teams. |
| Site Reliability Engineering | Production System Stability | Monitoring live environments, managing error budgets, and conducting blameless postmortems. |
| Operational Framework | Primary Goal | Team Structure |
| FinOps Management | Cloud Cost Optimization | Uniting finance, engineering, and business leadership into a continuous cost-governance loop. |
| DevOps Framework | Software Delivery Velocity | Unifying development and operations teams to automate continuous integration and deployment pipelines. |
Can You Have Both Disciplines?
Modern enterprises do not have to choose between different engineering approaches; instead, they successfully run them together. Platform engineering teams construct the core automation foundations and self-service portals that software developers use to ship code independently. Simultaneously, cost-optimization and reliability specialists analyze those active systems to ensure they run safely and remain financially sustainable. This collaborative multi-disciplinary approach allows companies to accelerate software innovation while maintaining complete control over platform health and infrastructure budgets.
Which One Should Your Team Adopt?
Choosing the right operational framework depends heavily on your current company size, engineering maturity, and cloud infrastructure budget. Early-stage startups with simple applications should focus on core DevOps automation to maximize software delivery speeds. However, as an organization scales up and its monthly cloud investments grow, implementing structured cost optimization becomes critical. Large enterprises running complex distributed microservices generally benefit from deploying dedicated reliability and cloud financial management teams to protect corporate margins.
Real-World Use Cases of Modern Operations
How Tech Leaders Use Operational Metrics
Major software enterprises manage their global digital footprints by converting real-time telemetry data into actionable business intelligence. These market leaders connect their infrastructure monitoring systems directly to corporate financial forecasting tools, tracking cost metrics across individual departments. If a specific product feature begins consuming an excessive amount of database storage, the system alerts product managers immediately. This granular visibility allows corporate executives to make accurate, data-driven decisions regarding product pricing, feature prioritization, and infrastructure investments.
Chaos Engineering Approaches to Resilient Systems
Top-tier technology organizations do not wait for random infrastructure outages to test the resilience of their distributed applications. Instead, they use chaos engineering practices to inject controlled failures into live production environments during regular business hours. Automated tools intentionally shut down random cloud servers, introduce artificial network latency, or disconnect primary database clusters. This proactive experimentation helps engineering teams discover hidden design vulnerabilities and optimize automated failover mechanisms before a real disaster strikes.
Handling Reliability at Massive Scale
Global digital streaming platforms and e-commerce giants handle millions of concurrent user transactions by building decoupled microservice architectures. These advanced systems use automated rate-limiting policies and circuit-breaker patterns to isolate localized component failures completely. If the user recommendation service slows down under heavy traffic, the core checkout system continues processing purchases smoothly. This architectural resilience ensures that large-scale infrastructure environments remain highly available, protecting corporate revenue streams during massive usage spikes.
High-Availability in Fintech Operations
Financial technology institutions operate under strict zero-tolerance mandates for system downtime, data loss, and transaction delivery delays. To meet these high compliance standards, fintech engineers deploy active-active multi-region cloud architectures that sync transaction data instantly. If an entire cloud data center goes offline due to a natural disaster, automated routing systems shift traffic immediately. This redundant engineering approach protects consumer accounts, ensures continuous payment processing capabilities, and keeps the institution compliant with strict global financial regulations.
Scaled-Down but Essential Systems for Startups
Early-stage technology startups can implement essential cost-optimization and reliability principles without needing massive engineering budgets or large dedicated teams. Founders leverage managed cloud services and automated budgeting alerts to keep their experimental infrastructure environments lean and highly visible. By setting up basic automated scheduling, startups spin down non-production testing environments automatically during weekends and evenings. This simple operational practice prevents unexpected cloud bill spikes, allowing early-stage companies to conserve valuable venture capital.
Common Mistakes in Operations Engineering
Mistake 1 — Confusing System Management with Just Being On-Call
A major mistake companies make is treating infrastructure specialists as a glorified, reactive, 24/7 technical support helpdesk. When engineers spend all their time manually responding to constant system alerts, they cannot build long-term automation solutions. This reactive loop leaves the underlying architecture fragile, drives up operational costs, and causes severe team burnout. Organizations must protect engineering time, ensuring specialists spend at least half their time writing software code that eliminates systemic issues permanently.
Mistake 2 — Setting Unrealistic SLOs
Business executives frequently demand absolute perfection, pushing their engineering teams to achieve impossible 100% system uptime targets. However, pursuing unrealistic reliability goals slows down software innovation because teams become terrified of making system changes. Over-engineering platforms to achieve unnecessary levels of uptime also requires massive investments in redundant, expensive cloud hardware. Wise organizations set realistic reliability targets based on actual user satisfaction, keeping development speeds fast and cloud costs under control.
Mistake 3 — Ignoring Toil Until It’s Too Late
Ignoring repetitive manual tasks creates massive operational debt that can stall an organization’s software development pipelines entirely. When teams scale up their cloud systems without automating maintenance, manual workloads quickly grow to completely unmanageable levels. Engineers become trapped in an endless loop of manual server patching, user account management, and database cleaning tasks. This lack of automation chokes operational velocity, increases human error risks, and prevents the company from scaling its infrastructure efficiently.
Mistake 4 — Skipping Blameless Postmortems
When organizations foster a culture of blame, engineers instinctively hide technical mistakes and cover up system vulnerabilities to protect themselves. This fear prevents teams from identifying the true root causes of severe system outages and leaves operational flaws uncorrected. Without transparent, blameless postmortems, the exact same infrastructure failures continue to happen repeatedly, draining corporate engineering resources. Embracing a blameless culture allows teams to analyze errors honestly, build stronger automation tools, and improve system resilience.
Mistake 5 — Monitoring Without Actionable Alerts
Flooding engineering teams with a non-stop stream of noisy, non-critical telemetry notifications creates severe alert fatigue across the organization. When systems trigger high-priority pages for minor resource fluctuations that do not harm end users, engineers quickly learn to ignore them. Consequently, when a genuine, critical system outage occurs, the warning is frequently missed amidst the background noise, increasing system downtime. Teams should only configure pages for issues that require immediate human intervention to protect user experiences.
Mistake 6 — Not Involving Operational Engineers in the Design Phase
Bringing infrastructure specialists into the software development process only after an application is fully built is a costly mistake. When software developers build systems without operational input, they often create architectures that are highly unstable and expensive to run. Operational engineers must collaborate on product designs from day one to ensure systems are easy to monitor, scale, and optimize. This early partnership avoids expensive architectural rewrites, improves platform reliability, and keeps cloud spending lean from the start.
Essential Infrastructure Tools & Technologies
Monitoring & Observability
To maintain complete control over distributed cloud environments, modern teams rely on advanced monitoring and observability suites. Tools like Prometheus and Grafana work together perfectly to collect, store, and visualize real-time time-series performance metrics. For enterprise-grade multi-cloud tracking, platforms like Datadog and New Relic provide deep distributed tracing and automated log aggregation capabilities. These technologies allow engineers to observe data paths across thousands of microservices, identifying performance bottlenecks and unexpected cost anomalies instantly.
Incident Management
When critical infrastructure failures occur, organizations use specialized incident management platforms to coordinate their engineering responses. PagerDuty serves as a central operational routing engine, analyzing incoming system alerts and waking up the correct on-call engineers immediately. These platforms integrate directly with corporate communication tools, automatically spinning up dedicated incident response channels and tracking remediation timelines. Using these automated incident coordination hubs ensures teams minimize communication confusion, accelerate system recovery times, and document incidents accurately for future reviews.
CI/CD & Release Engineering
Automating the software delivery pipeline requires robust continuous integration and continuous deployment engines to ensure stable, predictable production releases. Jenkins remains a widely used automation server for building and testing software code variations across diverse corporate development environments. For modern cloud-native infrastructures, GitOps tools like Argo CD and Spinnaker automate application deployments directly into Kubernetes clusters. These release technologies ensure all infrastructure changes match approved software configurations, minimizing human error and maximizing deployment stability.
Chaos Engineering
Building truly resilient distributed systems requires software teams to experiment with controlled failures using specialized chaos engineering tools. Chaos Monkey, originally pioneered by industry leaders, automatically terminates random virtual machine instances within production environments to test self-healing capabilities. Modern engineering teams also utilize advanced fault-injection frameworks to simulate complex network latencies, disk failures, and region-wide cloud outages safely. Running these controlled chaos experiments helps organizations uncover hidden architectural bugs and validate automated system recovery workflows.
SLO Management
As modern enterprises adopt data-driven reliability frameworks, managing service level objectives requires dedicated technical tracking tools. Platforms like Nobl9 integrate directly with existing monitoring systems to calculate error budgets and track reliability metrics continuously. These specialized management tools provide clear visualizations showing exactly how much error budget remains before a service level objective is violated. Using automated objective tracking helps business executives and engineering leaders collaborate effectively on balancing software innovation speeds with baseline system safety.
How to Become an Operations Expert — Career Roadmap
Skills Every Specialist Must Have
Breaking into this highly technical field requires mastering a core set of foundational infrastructure engineering and software development skills. You must feel completely comfortable navigating the Linux terminal command-line interface and writing advanced scripting automation using Python or Go. Understanding core networking concepts, including DNS configurations, TCP/IP routing, load balancing strategies, and modern SSL/TLS security protocols, is also mandatory. Additionally, aspiring specialists must master infrastructure-as-code principles, learning to provision and manage cloud environments programmatically using tools like Terraform.
The Professional Learning Path
Your educational journey should begin by gaining a deep understanding of standard software development methodologies and local system administration practices. Next, transition into studying containerization technologies by learning how to package, test, and deploy applications using Docker. From there, move up to mastering container orchestration, gaining comprehensive hands-on experience managing distributed production workloads inside Kubernetes clusters. Finally, focus your studies on advanced reliability engineering patterns, cloud financial management strategies, automated telemetry design, and large-scale architectural governance models.
Certifications Worth Pursuing
Earning industry-recognized professional credentials validates your technical expertise and opens up lucrative career advancement opportunities in the global marketplace. Aspiring reliability professionals should pursue the Certified Kubernetes Application Developer (CKAD) and Certified Kubernetes Administrator (CKA) certifications. For cloud infrastructure optimization, securing advanced certifications from major providers like AWS, Microsoft Azure, or Google Cloud is highly valuable. Additionally, earning specialized foundational certifications focused on cloud financial management demonstrates your ability to build cost-efficient architectures.
Educational Resources with [PROVIDER_NAME]
Navigating the complex world of modern cloud infrastructure management requires access to structured, high-quality, and up-to-date educational materials. You can accelerate your professional development journey by exploring the comprehensive training programs and expert-led bootcamps available at Finopsschool. Their specialized learning paths cover everything from foundational cloud costing principles to advanced automation architectures and real-world system optimization strategies. Investing in these structured training resources gives you the practical skills needed to lead corporate infrastructure transformations successfully.
The Future of Systems Management
AI and Automation in System Optimization
The integration of machine learning algorithms into infrastructure management systems is changing how enterprises maintain digital platform stability. Future observability tools will leverage artificial intelligence to analyze massive streams of telemetry data, predicting system anomalies before outages occur. These smart systems can automatically isolate failing microservices, adjust scaling policies, and tune database configurations without requiring manual human intervention. This AI-driven automation accelerates root-cause analysis, minimizes production downtime, and helps organizations optimize cloud resource utilization with incredible precision.
Platform Engineering — The Evolution of Infrastructure
Platform engineering is quickly becoming the dominant operational paradigm, reshaping how modern enterprises organize their software development teams. Instead of forcing software developers to manage complex underlying cloud resources, dedicated platform teams build internal developer portals. These self-service platforms provide pre-configured, compliant, and cost-optimized infrastructure templates that developers can deploy with a single click. This structural shift removes operational friction, ensures consistent security guardrails, and allows product teams to focus entirely on shipping business value rapidly.
Management in Cloud-Native & Kubernetes Environments
As modern corporate architectures transition completely to cloud-native, microservices-based environments, managing infrastructure scale becomes increasingly complex. Orchestrating thousands of ephemeral containers across dynamic multi-cloud Kubernetes clusters requires deep automation, robust service meshes, and advanced networking solutions. Future engineering priorities will focus heavily on managing cluster cost granularly, securing container communications, and ensuring seamless cross-cloud data migrations. Mastery of these complex orchestration patterns will distinguish top-tier infrastructure specialists from traditional system administrators in the global market.
Operational Skills That Will Matter Most
The ideal profile for systems professionals is expanding beyond basic technical scripting to encompass holistic business and financial acumen. Future engineering leaders must be adept at translating technical infrastructure metrics directly into strategic corporate business impact and profit margins. Developing a deep expertise in real-time cloud financial data tracking, data compliance governance, and green computing sustainability will be essential. Specialists who can build highly resilient software delivery pipelines while keeping corporate infrastructure spending lean will command premium positions across the industry.
FAQ Section
- What is the difference between a traditional systems administrator and a modern reliability engineer?Traditional systems administrators focus primarily on manually configuring hardware servers, responding to individual support tickets, and maintaining local network infrastructures. Conversely, modern reliability engineers treat infrastructure completely as a software engineering problem, writing automated code to manage, scale, and self-heal distributed systems.
- How much software programming knowledge do I need to work successfully in cloud financial management?You need a solid, practical understanding of core software programming concepts and scripting languages like Python, Go, or Bash to automate cost-tracking tasks. While you do not need to build complex consumer applications, you must be able to write scripts that interact with cloud APIs.
- What are the typical salary trends for certified cloud infrastructure optimization specialists in the current tech industry?Certified optimization specialists and reliability engineers are among the highest-paid technical professionals in the global technology marketplace due to severe talent shortages. Senior engineers who can successfully reduce enterprise cloud spend while maintaining system uptime frequently command premium six-figure salaries and executive bonuses.
- Can you explain how an error budget helps a company launch new software features faster?An error budget provides a clear, data-driven framework that defines exactly how much system risk a development team can safely take. If the system is running stable and the error budget is full, developers can ship experimental features rapidly without needing manual approvals.
- Why is a blameless postmortem culture considered so vital for long-term corporate infrastructure stability?A blameless culture encourages engineering teams to report technical failures honestly and analyze system design weaknesses without fearing personal punishment or professional retaliation. This transparency allows organizations to discover the true root causes of operational outages and build automated fixes that prevent repeat incidents.
- How does implementing automated infrastructure scaling policies directly improve corporate financial efficiency?Automated scaling policies monitor real-time user traffic demands and dynamically adjust cloud computing allocations to match those operational requirements exactly. This ensures that the enterprise never pays for idle, wasted server capacity during low-traffic periods while maintaining excellent system performance during spikes.
Final Summary
Maintaining long-term digital platform health requires balancing rapid software innovation velocity with disciplined infrastructure cost optimization and system reliability frameworks. Modern enterprises must look past legacy operational silos and view cloud infrastructure as a dynamic engineering asset that requires continuous financial governance. By embedding real-time monitoring, data-driven error budgets, and robust automation into your development culture, you eliminate waste and protect corporate margins. Embracing these advanced system principles allows your business to scale operations confidently while maximizing the true value of cloud infrastructure investments.
Unlocking these powerful performance capabilities across your enterprise requires a structured, hands-on educational foundation led by proven industry infrastructure mentors. You can empower your entire engineering organization to master these advanced technical disciplines by partnering with the expert educators at Finopsschool. Their comprehensive training paths equip your teams with the modern skills needed to build resilient, automated, and financially efficient system architectures. Take the next strategic step in your technology career and explore their professional certification training courses today.